비유사성 측정을 위한 준거리 연산

초록
분류, 군집화, 추천 같은 다양한 데이터 분석은 데이터 항목의 비유사성 즉, 거리를 측정하는 것으로 시작한다. 데이터 집합의 거리관계는 항목들의 거리를 나타내는 거리행렬로 나타낼 수 있는데, 어떤 데이터 집합은 거리행렬을 구하기 어렵다. 준거리 조건은 삼각부등식을 만족하는 것으로 거리척도의 최소조건이다. 이 논문은 주어진 데이터 집합에서 준거리 관계를 생성하는 행렬연산 min_sum을 제안하고, 이 연산과 일반적인 거리척도를 위한 조건과의 관계에 대한 정리를 생성하였다. 그리고 이 연산이 데이터 집합으로부터 직관적으로 만든 잠재적 거리행렬을 준거리 조건을 만족하는 행렬로 변환함을 증명하였다. 의원들의 1년치 실제 투표 데이터를 사용한 투표성향 군집화에 적용한 결과 거리척도로서 효과적임을 확인하였다.
Abstract
Various data analysis, such as classification, clustering, and recommendation, begins by measuring the dissimilarity or distance of data items. The distance relation of the data set can be represented by a distance matrix indicating the distance of the items, but it is difficult to get the distance matrix of some data set. The quasi distance condition satisfies the triangular inequality and is the minimum condition of metric. We propose a matrix operation min_sum that generates a quasi-distance relation in a given data set and generated the theorem about the relation between this operation and the condition for general distance metric. Then we prove that this operation transforms the potential distance matrix intuitively created from the data set into a matrix satisfying the quasi-distance condition. It is confirmed that it is effective as a distance measure as a result of applying voting tendency clustering using 1-year actual voting data of lawmakers.
Keywords:
dissimilarity, quasi-distance, distance matrix, metric, clusteringⅠ. 서 론
군집화를 포함한 많은 데이터 분석에 비유사성 측정이 사용된다[1][2]. 흔히 비유사성(Dissimilarity), 유사성, 거리, 근접성(Proximity) 등을 구분하지 않고 사용하지만 각각은 다소 다른 의미를 갖는다. 거리는 떨어진 정도를 나타내므로 유사성을 직접 나타내지 않는다. 유사성 s는 거리 r의 역수를 이용해서 s = 1/(1 + r) 형태로 사용한다[1][3]. 근접성은 가깝다는 의미를 내포하므로 유사성을 나타내는 다른 말이나 비유사성/유사성을 포괄하는 의미로 종종 사용한다. 비유사성은 대상의 다른 정도를 나타내므로 거리에 의해 직접 측정할 수 있는 것이다.
데이터를 분석하는 행위는 결국 패턴 찾기다. 모든 것이 같다면 아무 할 일이 없다. 데이터 분석의 많은 응용은 각자가 가진 고유한 방법에도 불구하고 거리 즉 비유사성을 측정을 전제로 한다. 덩어리를 찾아내는 군집화, 어디에 속하는지를 찾는 분류는 물론이고 요즘 많이 연구되는 추천시스템 들은 우선 거리를 측정하는 것에서 시작한다. 그런데 거리를 측정하는 것이 항상 가능한 것은 아니다. 예를 들어 두 사람의 취향이 비슷한지를 알려면 거리를 재야하는데, 취향을 잰다는 것이 쉽지는 않다.
본 논문은 비유사성을 측정할 수 있는 거리 연산에 관한 것이다. 먼저 데이터 과학의 제 분야에서 일반적으로 사용하는 거리 연산에 대해 알아보고, 떨어진 정도를 나타내는 거리 척도를 위한 수학적 정의와 조건이 완화된 거리에 대해 소개한다. 다음으로 주어진 데이터에서 준거리 관계를 생성하는 행렬연산 min_sum을 제안하고 증명한다. 이를 데이터 군집화에 적용하여 비유사성 측정 수단으로서 효과를 정성적으로 평가한다. 제안한 준거리 연산을 사용하는 경우 국가 사이의 교역량, 사람들 사이에 주고받은 문자 횟수 등 일반적으로 거리를 정의하기 어려운 데이터에 거리 개념을 부여하여 분류 및 군집화 등을 수행할 수 있다.
Ⅱ. 준거리 생성을 위한 행렬연산 min_sum
이 장에서는 거리에 대한 일반적인 정의와 비유사성 측정을 위해 흔히 사용하는 거리함수에 대해 설명한다. 다음으로 새로운 행렬연산 min-sum을 제안하고 이것이 준거리 조건을 만족하는 거리행렬을 생성함을 증명한다.
2.1 거리에 대한 정의
분류, 군집화, 추천시스템 등 데이터 분석의 많은 분야는 대상의 비유사성을 측정하기 위해 다양한 거리 척도를 사용한다. 많은 응용에서 사용하는 거리 척도는 다음과 같으며 이들의 일반적인 특징에 대해 오랫동안 연구되어 왔다[4]-[6].

Distance functions
항상 그렇듯이 모든 데이터의 비유사성을 잘 측정하는 거리 척도는 없으며 응용에 따라 다르게 평가된다[2][5][7]. 하지만 이들은 거리를 측정하는 함수로서 모두 일정한 조건을 만족한다. 비유사성을 위한 거리 척도로서 거리함수는 일반적으로 다음과 같이 정의한다.
정의1 집합 X와 함수 d : X×X→[0,∞)가 모든 x, y, z∈X에 대하여 다음 네 가지 조건을 만족하면 d를 X위의 거리 혹은 거리함수 라고 한다.
(M1) d(x,x) = 0
(M2) d(x,z) ≤ d(x,y) + d(y,z)
(M3) d(x,y) = d(y,x)
(M4) d(x,y) = 0이면 x = y이다.
함수 d가 M1, M2 두 조건만 만족하면 준거리(Quasi-distance)라 부르고, d가 M1, M2, M3 세 조건을 만족하면 왜곡거리(Pseudo-distance)라 부른다. 준거리와 왜곡거리는 거리의 개념을 더 일반화한 것이다. 특히 준거리는 비유사성 측정을 위한 척도의 최소 조건을 만족한다[5][8]. 표 1에서 앞에서부터 5개는 모두 정의1을 만족하는 거리함수다. 반면에 상관계수 rij(*)와 cosα(**)는 유사성을 나타내는 것으로 거리가 아니다. 따라서 비유사성 척도로 사용할 때는 다음과 같이 변환한다.
| (1) |
거리함수를 이해하기 위해 몇 가지 사례를 설명한다. 어떤 집합 X에 대하여 X ×X위에서 로 정의된 함수는 정의1을 모두 만족하므로 X위의 거리다. 다음으로 정수의 집합 Z에 대하여 Z ×Z위에서 로 정의된 함수는 예를 들어 d(1,3) ≠ d(3,1)이므로 조건 M3를 만족하지 않아서 거리가 아니다. 하지만 다른 조건들은 모두 성립하므로 준거리이다. 마지막으로 평면 R2위의 두 점 x= (x1, y1 ), y =(x2, y2)에 대하여 d(x,y) = |x1 - y1|으로 정의된 함수는 M1, M2, M3를 만족하므로 왜곡거리이다. 하지만 서로 다른 두 점에 대하여 d((2,2),(2,3)) = 0이므로 M3를 만족하지 않아 거리가 아니다.
2.2 행렬연산 min_sum
이 논문에서 제안하는 거리연산 min_sum은 다음과 같다.
정의2 집합 X = {a1,⋯,an}위에서 정의된 함수 d : X×X→[0,∞)에 대하여 행렬 A = (aij), aij = d(ai,aj)에 대한 연산 min_sum을 다음과 같이 정의한다. 여기서 ⊕은 연산 min_sum을 나타내는 연산자이고 는 k = 1, 2, ⋯, n에서 최솟값을 의미한다.
| (2) |
앞에서 정의한 연산 ⊕에 대해 다음 정리를 얻을 수 있다. 앞으로 필요충분조건(if and only if)은 간단히 iff 로 나타낸다.
- 정리1 정의2의 함수 d는 다음을 만족한다.
- (1) d(ai,ai) = 0 iff aii = 0, i∈{1,⋯,n}
- (2) d(ai,aj) ≤ d(ai,ak) + d(ak,aj)
iff aij ≤ aik + akj, k∈{1,⋯,n} iff aij ≤ cij. - (3) d(ai,aj) = d(aj,ai) iff aij = aji, i,j∈{1,⋯,n}
- (4) d(ai,aj) = 0 ⇒ ai = aj
iff aij = 0 ⇒ i = j.
- 증명
- (1) 정의2에 의하여 성립한다.
- (2) d(ai,aj) ≤ d(ai,ak) + d(ak,aj)이라고 가정하면 aij ≤ aik + akj , k∈{1,⋯,n}이다. 따라서 이다. 역으로 aij ≤ cij이면 aij ≤ aik + akj, k∈{1,⋯,n}이다. 따라서 d(ai,aj) ≤ d(ai,ak) + d(ak,aj)이 성립한다.
- (3) 정의2에 의하여 d(ai,aj) = d(aj,ai)이면 aij =aji , i,j∈{1,⋯,n}이고, 역도 성림한다.
- (4) d(ai,aj) = 0일 때 ai = aj이라고 가정하자. aij = 0이면, d(ai,aj) = 0이므로 ai = aj이고, i = j가 성립한다. 역으로 aij = 0일 때 i = j가 성립한다고 가정하면, d(ai,aj ) = 0이면 aij = 0이므로 i = j이고, 따라서 ai = aj이다. QED
2.3 연산 ⊕를 반복 적용하여 준거리 생성
다음 정리는 행렬연산 ⊕를 반복 적용하면 준거리를 생성할 수 있음을 보여준다.
- 정리2 집합 X = {a1,⋯,an}위의 거리함수 d : X×X→[0,∞)가 조건 (M1)을 만족하고 행렬 A 가 A = (aij) , aij= d(ai,aj)이면,
- 일 때,
- 가 존재한다.
- 증명
- 정리1에 의해, 다음이 만족한다.
즉, 은 감소수열이고 아래로 유계이므로 수렴한다. QED
따라서 다음이 성립한다.
- 이면
- 이면
- 이면
⋯ - 이면
정의2와 정리2의 2)에 의해 우리는 거리 조건 M1을 만족하는 행렬에 제안한 min_sum 연산 ⊕를 반복적용하면 준거리 관계를 만족하는 행렬 D를 생성할 수 있음을 알았다. 제안한 연산이 비유사성 즉 거리 척도로 사용될 수 있음을 보이기 전에 한 가지 사례를 통해 정리2의 의미를 이해해 보자.
지난 1주일 동안 a1은 a2, a3, a4에게 7, 3, 4번, a2는 a1 , a3 , a4에게 3, 4, 2번, a3는 a1, a2 , a4에게 8, 3, 1번, 마지막으로 a4는 a1, a2 , a3에 5, 2, 1번 전화를 했다고 하자. 보다 친밀한 혹은 가까운 사람에게 자주 전화를 한다고 가정하면 네 사람 사이의 거리를 행렬 F로 나타내는 것을 생각할 수 있다.
| (3) |
그러나 행렬 F는 예를 들어 d(a3,a2 ) = 1/3≰d(a3,a1 ) + d(a1,a2 ) = 1/8 + 1/7 = 15/56이므로 준거리조차 되지 못한다. 따라서 행렬 F는 주어진 데이터의 거리 관계를 나타내는 행렬로 사용할 수 없다. 그러나 F에 min_sum 연산 ⊕를 적용한 F⊕F는 준거리다. 실제로 F⊕F는 정의1의 M1, M2, M4를 만족한다. 따라서 행렬 F⊕F은 비유사성을 측정하는 거리행렬로 사용할 수 있다.
Ⅲ. 성능 평가 및 분석
비유사성/유사성에 대해서는 주로 통계학의 분야에서 70년대까지 잘 정리되었다. 이어진 연구들은 특정 문제와 관련해서, 데이터 유형 즉, 수치데이터, 이진데이터, 범주형데이터, 혼합형데이터 등을 대상으로 비유사성 척도들을 어떻게 활용하는지 등에 관한 것이다[8][9]. 비유사성 척도를 정량적으로 비교하기는 어렵다. 비유적으로 사람을 비교하는데 키와 몸무게 중 어떤 것이 유용한지는 어디에 사용하느냐에 달린 문제다. 여기서는 ⊕연산이 상대적인 거리를 효과적으로 측정한다는 것을 정성적인 방법으로 보인다. 앞의 사례를 잘 살펴보면 직관적으로 a3는 a4 , a2보다 a1과 가깝다고 생각되지만 이를 정량적으로 판단하려면 거리를 구할 수 있어야 한다. 하지만 앞에서 본 것과 같이 주어진 데이터 항목의 거리관계를 나타낼 마땅한 방법이 없다. 대신 제안한 ⊕연산을 사용하여 준거리를 생성할 수 있음을 알았다.
그림 1은 이렇게 구한 행렬 F⊕F의 거리 관계를 MDS(Multi-Dimentional Scaling)을 이용해서 나타낸 것이다. MDS는 비유사성 즉, 거리가 정해진 데이터를 시각적으로 나타내는 일종의 그래프 레이아웃이다[3]. 넓은 의미에서는 높은 차원 데이터의 차원을 낮추는 것인데, 여기서는 평면에 나타내는 것이므로 2차원으로 낮춘다. 즉, 거리행렬을 입력으로 받아서 데이터 들 사이의 거리를 가장 잘 반영하는 좌표를 생성해준다. R 프로그래밍에서 제공하는 cmdscale() 함수를 사용하여 거리관계를 시각적으로 나타냈다. 그림은 a3와 a1이 상대적으로 가깝다는 것을 보여준다.

Visualization distance relation in F⊕F
이상으로 ⊕연산으로 준거리를 생성하고 그것을 시각적으로 나타내 보았다. 이제 더 복잡한 데이터 집합의 군집화에 제안한 연산을 적용해 본다. 사용한 데이터는 미국 상원의 기명 투표 데이터다(http://www.voteview.com). 미국 상원 의원은 공화당, 민주당, 무소속으로 구성된다. 여기서는 투표 데이터를 군집화 하여 투표성향과 소속정당의 관계를 알아보려고 한다. 즉, 의원들의 법안에 대한 투표 데이터를 이용하여 의원들 사이의 거리를 구한 후 소속정당과 함께 시각적으로 나타내었을 때 군집이 형성되는지 알아보려 한다.
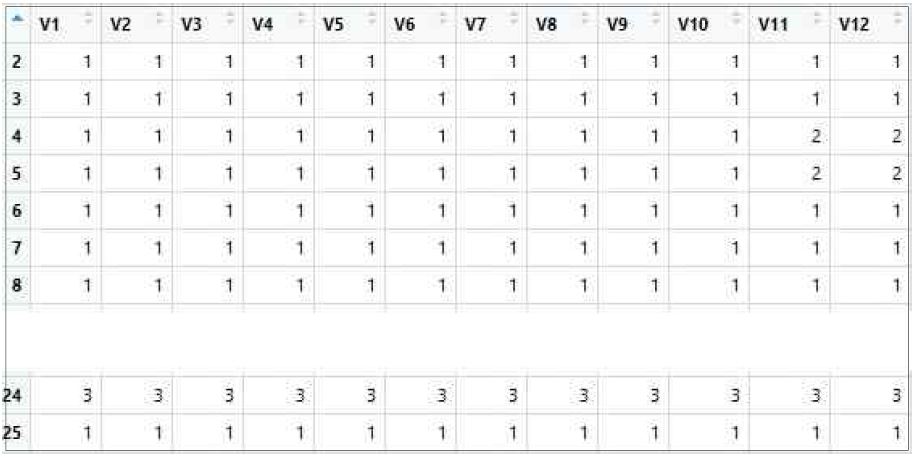
원 데이터의 편집과 클러스터링 과정은 참고문헌[3] 9장의 절차를 참고하였다. 표 2는 의원-투표 데이터 행렬을 나타낸다. 109번 회기를 기준으로 이 행렬의 크기는 101×644이다. 즉, 의원 101명이 644건의 법안에 투표한 결과다. 여기서 1은 찬성, 2는 반대, 3은 기권을 나타낸다. 어떤 두 의원의 벡터열이 일치할수록 두 의원의 투표성향이 같다고 할 수 있다. 따라서 일치하는 정도를 거리로 나타내면 투표성향이 같은 의원은 가까이 위치할 것이다. 이 때 각 의원의 위치를 소속정당으로 표시하면 투표 성향이 같은 사람들이 어떻게 분포하는지를 알 수 있다.
Senator-Vote data matrix
[3]에서는 의원들 사이의 거리를 의원-투표 행렬의 행 벡터별 유클리드 거리를 계산하여 측정하였다. 그림 2는 R 프로그램 결과를 나타낸다.

Distance of senators(Euclid)
예를 들어 2번 의원(첫 번째)과 3번 의원 사이의 거리가 약 10임을 나타낸다. 또한 거리행렬은 대칭이므로 하삼각행렬로 표시되었음을 알 수 있다.
이제 이렇게 계산한 의원들 사이의 거리를 2차원 평면에 펼쳐놓으면 그들의 소속정당별 분포를 알 수 있다. 그러기 위해서 MDS를 적용하여 각 의원들의 좌표를 구한 결과는 표 3과 같다. 예를 들어 SHELBY의원은 민주당 소속이고 상대적 거리를 고려했을 때 위치좌표는 대략 (7.5, 0.95)임을 나타낸다.
Coordinate of senators(Euclid)
이 결과를 시각화 하면 그림 3과 같다. 왼쪽에 민주당, 오른쪽에 공화당 의원이 군집을 형성함을 알 수 있다.

Cluster(Euclid)
제안한 min-sum 연산을 적용하려면 먼저 의원들 사이의(잠재적) 거리를 나타내는 의원-의원 행렬을 구해야 한다. x-y 관계를 나타내는 데이터 행렬 M 이 주어지면 M*MT와 MT *M은 각각 x-x및 y-y관계를 나타내는 행렬이 된다(여기서 *는 행렬의 곱, MT는 전치행렬). 따라서 의원-투표 행렬로부터 의원-의원 행렬을 구할 수 있다. 물론 이 행렬은 정의1의 거리조건을 만족하지 않으므로 거리 척도로 사용할 수 없다. 기존의 연구에서는 이렇게 얻은 의원-의원 행렬에 대해 행 벡터별 유클리드 거리를 계산하여 거리 행렬을 만드는 번거로운 과정을 거친다[3][7].
이제 의원들 사이의 준거리를 만들어 보자. 의원-투표 행렬을 M이라 하면, 의원-의원 행렬 N=M*MT을 얻을 수 있다. 행렬 N의 대각성분을 0으로 수정한 행렬을 N(0)라 하면 정리2에의해 준거리 Q = [N(0)⊕N(0)]m를 얻을 수 있다. 실제로 이 경우 m = 1이다. 그림 4, 표 4, 그림 5는 이렇게 구한 준거리 행렬 Q를 같은 방법으로 MDS로 시각화한 것이다.

Distance of senators(min_sum)
Coordinate of senators(min_sum)

Cluster(min_sum)
그림 3과 마찬가지로 의원들의 투표성향이 소속 정당별로 군집을 형성함을 알 수 있다. 즉, 제안한 연산으로 생성한 준거리가 데이터의 특정속성을 분석하기에 적절함을 알 수 있다.
Ⅳ. 결 론
분류, 군집화, 추천 같은 데이터 분석의 다양한 분야가 데이터 항목의 비유사성 즉, 거리 측정을 필요로 한다. 데이터 집합의 거리관계는 항목들의 거리를 나타내는 거리행렬로 나타낼 수 있다. 데이터 집합이 항목-값 행렬로 주어지는 경우, 보통 항목벡터들의 유클리드 거리, 상관계수, 코사인 유사도 등을 이용하여 거리행렬을 구하는데, 이는 계산량이 많기도 하고, 직관적이지도 않다. 이 논문에서는 데이터 집합으로부터 직관적으로 만든 잠재적 거리행렬을 준거리 조건을 만족하는 행렬로 변환하는 행렬연산 min_sum을 제안하고, 이 연산을 반복 적용하면 준거리 행렬로 수렴함을 증명하였다. 제안한 연산을 군집화에 적용한 결과 종전의 방법과 같이 거리 척도로서 효과적임을 확인하였다.
이 논문에서는 제안한 행렬연산 min_sum이 거리 조건을 만족하지 않는 행렬을 준거리 조건을 만족하는 행렬로 변환함을 증명하고, 그렇게 얻어진 거리행렬이 비유사성을 효과적으로 측정함을 실제 문제에 적용하여 정성적으로 확인하였다. 다음으로 동일한 데이터에 대해 통상의 방법으로 생성한 거리행렬과 제안한 연산을 적용하여 생성한 준거리 행렬을 데이터 유형별로 분석하는 연구와 계산 복잡도를 비교하는 연구가 수행될 수 있겠다.
Acknowledgments
이 논문은 2016년도 광운대학교 교내학술연구비 지원에 의해 연구되었음
References
- A. D. Gordon, "Classification : Methods for the Exploratory Analysis of Multivariate Data", Measuring Dissimilarity, Chapman and Hall, Chap 2, p13-32, (1981).
- Rui Xu, and Donald Wunsch II, "Survey of Clustering Algorithms", IEEE Transactions on Neural Networks, 16(3), p645-678, May), (2005.
- Drew Conway and John White, "Machine Learning for Hackers", O'Reilly Media, p241, Feb), (2012.
-
J. C. Gower, "A General Coefficient of Similarity and Some of Its Properties", Biometrics, 27(4), p857-871, Dec), (1971.
[https://doi.org/10.2307/2528823]

-
J. C. Gower, and P. Legendre, "Metric and Euclidean Properties of Dissimilarity Coefficients", Journal of Classification, 3(1), p5-48, Mar), (1986.
[https://doi.org/10.1007/bf01896809]
- Guojun Gan, Chaoqun Ma, and Jianhong Wu, "Data Clustering : Theory, Algorithms, and Applications, Similarity and Dissimilarity Measures, ASA-SIAM Series on Statistics and Applied Probability", SIAM, Philadelphia, ASA, Alexandria, VA, p67-106, (2007).
- Segaran, and Toby, "Programming Collective Intelligence: Building Smart Web 2.0, Applications", O’Reilly Media, p14, (2007).
- Brian S. Everitt, Sabine Landau, Morven Leese, and Daniel Stahl, "Cluster Analysis", 5th Ed., John Wiley & Sons, Ltd, p49, (2011).
- Charu C. Aggarwal, and Chandan K. Reddy, "Data Clustering Algorithms and Applications", CRC Press, p7, (2014).

1985년: 연세대학교 수학과 (이학사)
1988년: 고려대학교 전산과학과 (이학사)
1991년: 고려대학교 수학과 (이학석사)
1996년: 고려대학교 컴퓨터학과 (이학박사)
1997년 ~ 현재 : 강릉원주대학교 컴퓨터공학과 교수
관심분야 : 복잡계, 인공생명, 인공지능, 소프트컴퓨팅

1985년 : 연세대학교 수학과 (이학사)
1987년 : 연세대학교 수학과 (이학석사)
1994년 : 연세대학교 수학과 (이학박사)
2003년 ~ 현재 : 광운대학교 인제니움학부대학 교수
관심분야 : 수치해석, 정보수학, 인공지능

1982년 : 연세대학교 수학과 (이학사)
1984년 : 연세대학교 수학과 (이학석사)
1991년 : 연세대학교 수학과 (이학박사)
1991년 ~ 현재 : 강릉원주대학교 수학과 교수
관심분야 : 정보수학, 퍼지수학