도장 품질 관리 및 에너지 효율화를 위한 AI 기반 온도 예측 모델 비교 연구 : 조선소 사례
 ; 이대겸*
; 이재섬**
; Daekyeom Lee*
; Jae-Sum Lee**
; 이대겸*
; 이재섬**
; Daekyeom Lee*
; Jae-Sum Lee**
초록
본 연구는 제한된 공정 데이터 환경에서 도장의 온도를 예측하기 위한 머신러닝 및 딥러닝 모델의 성능을 비교 분석하였다. 작업동 센서 데이터와 ASOS 기상 데이터를 결합하여 Ridge, Lasso, Random Forest와 같은 머신러닝 기법 모델과 RNN, LSTM과 같은 딥러닝 기법 모델의 평가를 진행하였다. 평가 시에는 보수적인 조선소 운영 환경을 고려하여 단순 정확도 뿐만 아니라 예측 변동성과 통계적 유의성을 함께 검토하였다. 연구 결과, 순환 신경망 모델들이 높은 안정성과 우수한 예측 성능을 보여주었다. 이러한 결과는 도장 품질 향상과 에너지 효율화를 위한 스마트 조선소 운영 전략 수립에 기여할 것으로 기대되며, 향후 이를 기반으로 한 고도화 연구를 수행하고자 한다.
Abstract
This study compared and analyzed the performance of machine learning and deep learning models for painting temperature prediction in a limited process data environment. Ridge, Lasso, Random Forest, RNN, and LSTM were evaluated by combining working motion sensor data and ASOS weather data, and predictive volatility and statistical significance were evaluated as well as accuracy in consideration of the conservative shipyard operation environment. As a result of the study, recurrent neural network models showed high stability and prediction. These results are expected to contribute to the establishment of a smart shipyard operation strategy for improving painting quality and energy efficiency, and we intend to conduct advanced research in the future.
Keywords:
machine learning, deep learning, temperature prediction, shipbuilding, energy optimizationⅠ. 서 론
조선업의 도장 공정 온도 관리는 도장 품질과 생산성 확보에 필수적이다[1][2]. 선박 도장 공정은 외부 환경(온도, 습도, 기상조건 등)에 크게 좌우되며, 도료의 적정 건조를 위해서는 정교한 온도 관리가 요구된다.
전통적으로 현장에서는 경험기반의 단순 온도 제어로 공정을 관리해 왔지만, 외부 온도, 습도, 환기 상태 등 복합 변수를 정량적으로 예측하기에는 분명한 한계가 있다. 최근 인공지능(AI) 기반 시계열 모델의 발전으로 제조업 전반에 환경 예측 기술 도입이 시도되고 있지만, 조선소 도장 공정을 대상으로 한 온도 예측연구는 국내·외적으로 거의 전무하다.
본 연구는 조선소의 제한된 데이터 환경에서 단순히 높은 예측 정확도를 넘어, 실제 산업 현장의 동적 특성을 반영할 수 있는 모델이 무엇인지 비교·분석하는 것을 목표로 한다.
현장에서 성공적인 예측 모델은 높은 평균 정확도를 달성해야 한다. 또한 예측 결과의 변동성이 낮아 공정 관리의 신뢰성을 확보하고, 지속적으로 축적되는 데이터에 대한 장기 학습 능력과 안정성도 갖춰야 한다. 이를 위해 전통적 머신러닝 모델Lasso, Ridge, Random Forest과 딥러닝 모델 RNN (Recurrent Neural Network), LSTM(Long Short-Term Memory)을 동일 데이터셋에서 교차 검증하고, 평균 정확도뿐 아니라 예측 결과 변동성, 장기 학습 능력 및 안정성을 포함한 다차원 평가 기준에 따라 비교·분석한다.
이러한 접근은 조선 도장 공정에 AI 기반 온도 예측을 최초로 적용했다는 점에서 학문적·실무적 의의가 크다. 또한 도장 공정 최적화를 통해 품질 및 생산성 향상과 스마트 조선소 전환에 기여할 수 있다.
논문의 구성은 다음과 같다. 2장에서는 관련 연구를 검토한다. 3장에서는 데이터 수집·전처리 및 모델 설계 방법을 제시한다. 4장에서는 실험 결과와 분석을, 5장에서는 결론 및 향후 연구 방향을 다룬다.
Ⅱ. 관련 연구
2.1 제조업의 온도 예측을 위한 인공지능 활용
스마트 팩토리 구현과 함께 제조공정 온도 예측 연구가 활발해지고 있다[3]. 화학 공정에서는 딥러닝으로 증류탑 내부 온도를 예측하여 제품 품질과 운전 효율을 개선한 연구가 보고되었고[4], 식품 공장에서는 LSTM 기반 냉장고 온도 예측을 통해 에너지 관리 효율화를 달성했다[5].
2.2 순환신경망 중심의 시계열 예측 연구
순환신경망(RNN)은 시계열 데이터의 시간적 종속성을 학습하는 모델로, 이전 시점 정보를 현재 예측에 반영한다. 온도 예측 분야에서 RNN은 기존 ARIMA나 회귀 모델 대비 향상된 성능을 보였으나, 장기 시퀸스 학습 시 기울기 소실 문제로 인해 장기 의존성 학습에 한계를 보였다[6]. RNN의 한계를 극복하기 위해 개발된 LSTM은 게이트 메커니즘을 통해 장기 의존성 학습에 특화되었으며, 비선형적 환경 데이터 변동에도 안정적으로 학습한다[7]. LSTM은 여름철 온도 예측[8], 화학공정 증류탑 온도 예측[4], 에너지 소비 예측[9], 실내 온도 예측[10], 도시 공공시설 환경 제어[11]등에서 우수한 성능을 입증했다.
2.3 조선업 분야에서의 관련연구
타 제조 분야와 달리 조선소의 개별 공정에 대한 시계열 예측 연구는 아직 부족하다. 기존 연구들은 주로 선택적 앙상블 학습을 활용한 선박 도장 작업 시간 예측[2], 전이학습 기반 조선소 블록 제조 시간 예측[12], 조선소 생산 데이터의 머신러닝 기반 리드타임 예측[13]등에 집중되어 왔다. 이들 연구는 조선소 내 제조 공정의 시계열 예측 가능성을 보여주지만, 도장 공정의 온도 관리에 대한 연구 사례는 찾아보기 어렵다. 이는 대형 구조물 처리, 복잡한 공정 환경, 데이터 수집 여건의 제약 때문으로 추정된다[14].
Ⅲ. 연구 방법론
3.1 데이터 수집
본 연구는 조선소 도장 공정의 온도 예측을 위해 선행도장공정이 진행되는 각 작업동의 센서 데이터와 동일 시간의 대한민국 기상청 종관기상관측(ASOS) 데이터를 수집했다. 작업동의 센서 데이터는 EE300Ex-M1이라는 산업용 방폭 온습도 노점계로부터 수집되었으며 2021년부터 2023년까지 매년 5월과 10월, 하루 24회(1시간 간격) 측정된 데이터를 대상으로 하였다. 해당 센서 데이터는 각 작업동의 내·외부 온도 및 습도를 포함하고 있다. ASOS 기상 데이터는 해당 조선소의 동일지역 관측소에서 수집된 기온(℃), 습도(%), 풍향(16방위), 풍속(㎧), 강수량(㎜), 일사량(MJ/㎡), 일조(hr), 현지기압(㍱) 등 외부 환경 변수를 포함하고 있다.
3.2 데이터전처리
수집된 원천 센서 데이터는 센서 오류, 통신 지연 등의 이유로 결측치와 노이즈를 포함하고 있어 데이터 정제 과정이 필수적이었다. 우선 선행 도장 공정 작업동(A, B, C)의 내부 온도 및 외기 온도 변수를 중심으로 날짜와 시간 형식을 표준(ISO 8601)으로 통일했다. 불필요한 표식 문자(예: ‘***’)는 결측치(NaN)로 변환한 뒤, 앞뒤 관측값의 평균으로 보간(Imputation)하여 데이터의 시간 연속성과 패턴 유지 가능성을 확보하였다. 그리고 공장 내부 습도관리를 위해 제습기가 가동되는 시간대(00:00-04:00)는 예측 정확도에 불필요한 영향을 줄 수 있으므로 학습 대상에서 제외하였다. ASOS 기상 데이터 또한 시간 스탬프 형식으로 처리하여 센서 데이터와 동일한 시간축의 시계열 데이터셋을 구축하였다. 환경 변수 중에서 결측치 비율이 높거나 관측 누락이 빈번한 변수는 학습 입력 변수에서 배제하였다. 이를 통해 최종적으로 구성된 입력 변수는 기온(℃), 풍속(㎧), 현지기압(㍱) 등 예측에 실질적으로 기여할 수 있는 항목들로 제한하였다.
마지막으로 입력 변수 간 스케일 차이에 따른 모델 수렴 불안정성을 해소하고, 학습 성능을 극대화하고자 MinMax, Standard, Robust, Normalizer, MaxAbs 스케일링 기법을 비교 적용했다.
3.3 모델 설계 및 구현
전처리된 데이터를 기반으로 기초 통계 분석, 패턴 분석을 수행하여 모델 설계 방향을 설정한다. 그림 1의 기초 통계 분석 결과에 따르면, 5월 평균 온도는 작업동 A, B, C와 외기 간의 큰 차이가 없었으나 최대·최소 온도에서는 외기 온도가 내부 온도보다 큰 폭을 보이고 있다. 이는 도장동 내부의 밀폐 구조와 잔열 효과에 따른 열 축적 현상을 반영한 결과로 볼 수 있다. 반면, 10월의 평균 온도는 작업동 A, B, C와 외기 간에 약 2~3℃ 차이를 보였으며 최대·최소 온도에서도 외기 온도가 내부 온도보다 상대적으로 낮은 온도를 유지하고 있다. 또한 온도의 표준편차는 10월이 5월보다 전반적으로 높게 나타나, 가을철의 일교차 증가가 작업 공간 온도에 영향을 미쳤음을 시사한다. ASOS 기상 데이터 분석 결과에서도 5월보다 10월의 평균 온도가 약 2℃ 낮았으며 평균 일조 시간, 지면 온도, 운량도 약 20% 정도 낮았다. 반대로 습도나 현지 기압, 증기압은 10월이 미세하게 더 높거나 크게는 약 10% 정도 더 높았는데 이는 계절별 대기 순환의 특성을 잘 보여주는 결과로 볼 수 있다. 대부분의 기상 요소에서 10월의 표준편차가 5월보다 작게 나타나면서 전형적인 가을철 이동성 고기압의 영향으로 맑고 건조하고 안정된 날씨를 보였고, 5월은 봄철의 특성상 기상 변화가 크고 대류 활동이 활발한 불안정한 날씨 패턴을 보였다.

Temperature distribution and descriptive statistics (May and October)
더불어 월별 일평균 온도의 추세 및 패턴 변화를 분석하여 온도의 단기적인 변동성과 계절적 흐름을 보다 명확하게 파악하고자 했다. 그림 2를 보면 5월은 모든 작업동(A, B, C)에서 일관적으로 점진적인 상승 추세를 나타냈고 반대로 10월에는 점진적인 온도 하강 추세를 보였는데 이는 일조 시간의 단축, 기온 하강 등의 계절 요인이 반영된 결과로 보인다. 전반적으로 A, B, C는 시계열 곡선의 형태, 변동, 상승 및 하강의 시점이 거의 동일하며 비슷한 패턴을 보이고 있으나 외기 온도는 비교적 변동성이 크며 불규칙한 특성을 나타내어, 실내 온도와 비교했을 때 외부 환경의 영향을 더 크게 받는 것으로 분석된다.

Monthly average daily temperature trend analysis
예측 모델 학습을 위해 시계열 입력 데이터를 과거 관측값 기반의 Supervised Time-Series Forecasting 형태로 구성하였다. 입력 시퀀스는 슬라이딩 윈도우 방식을 적용하여 생성하였으며, 이는 모델이 시간의 흐름에 따른 비선형 패턴과 계절성 변동을 학습할 수 있도록 설계되었다. 각 작업동별 입력 변수는 상관관계와 다중공성선를 통해 선택되었으며, 모델 학습에 사용된 주요 입력 및 타겟 변수는 아래 표 1과 같다.

Organizing data for model training
시계열 온도 예측을 위해 머신러닝 모델로 라쏘 회귀, 릿지 회귀, 랜덤 포레스트 회귀 모델을 적용했다. 선형 회귀 기반의 라쏘 및 릿지 모델은 각각 L1, L2 정규화를 적용하여 과적합을 방지하고 모델의 안정성을 높이는 데 사용했다. 구체적으로 라쏘는 불필요한 변수의 계수를 0으로 만들어 모델을 단순화하는 효과가 있고, 릿지는 모든 변수를 활용하되 계수 크기를 조정하는 특징을 가진다. 한편, 랜덤 포레스트 회귀는 다수의 결정 트리를 결합한 앙상블 모델로, 변수 간의 복잡한 비선형 관계를 효과적으로 학습하기 위해 활용했다. 또한 이 모델은 변수의 스케일에 민감하지 않아 별도의 정규화 과정 없이 예측을 수행할 수 있는 장점이 있다.
이와 더불어 시계열 데이터의 시간적 종속성을 명시적으로 학습하기 위해 딥러닝 모델을 추가로 적용했다. 딥러닝 모델로는 순환 신경망(RNN)과 장단기 기억 네트워크(LSTM)를 활용했다. RNN은 이전 시점의 정보를 순환 구조로 반영하여 미래값을 예측하는 모델이며, LSTM은 이러한 RNN을 확장하여 장기 의존성 학습에 특화된 모델이다. 특히 LSTM은 기존 RNN의 기울기 소실 문제를 해결하여, 복잡한 시계열의 장기적인 패턴을 효과적으로 학습할 수 있는 강점을 가진다.
3.4 학습 검증 절차
본 연구에서는 조선소 도장 공정의 내부 온도 예측을 위한 모델 학습 및 평가에 있어, 시계열 데이터의 순차성과 실제 적용 환경을 반영한 학습 검증 절차를 수행하였다. 시계열 예측의 일반화 가능성과 현실 적용성을 확보하기 위해 전체 데이터를 미래 정보가 이전 시점에 유입되지 않도록 시간순으로 분리하여 학습, 검증, 테스트 데이터셋으로 구성하였다. 모든 전처리 및 정규화는 학습 데이터셋을 기준으로 수행된 후 동일 파라미터를 검증 및 테스트 데이터셋에 적용했다. 랜덤 서치 방식으로 최적화했으며 머신러닝 모델 학습 시 릿지 모델의 alpha값은 1, 라쏘 모델의 alpha값은 0.1로 설정하였고, 랜덤 포레스트 모델의 트리수는 100, 최소 샘플 수는 2로 설정하였다. 딥러닝 모델 학습 시 hidden size는 256, 층수는 2, 옵티마이저는 Adam, 손실함수는 MSE, 조기 종료방식은 검증 손실값 기준으로 설정하였다. 학습은 최대 100 에포크동안 수행되었으며, 배치 사이즈는 32로 고정하였다. 과적합을 방지하기 위해 드롭아웃 기법을 적용하였으며 비율은 0.2로 설정하였다. 모델의 성능 평가는 평균 절대 오차(MAE, Mean Absolute Error), 평균 제곱 오차(MSE, Mean Squared Error), 평균 제곱근 오차(RMSE, Root Mean Squared Error), 결정계수(R²), 백분율 상대 오차(MAPE, Mean Absolute Percentage Error) 등의 시계열 회귀 예측에 적합한 다양한 정량 지표를 활용하여 수행하였으며, 추가적으로 테스트 데이터셋을 기반으로 예측값과 실제값 간 오차가 ±2℃ 또는 ±3℃ 이내에 포함되는 비율을 분석하여 모델의 예측 정확도를 종합적으로 검토하였다. 훈련 및 검증 단계에서는 모델의 일반화 성능을 반복적으로 평가하기 위해 5-폴드 누적 평균 교차 검증(Cross-validation)을 적용했다. 이는 시계열 예측에 적합한 검증 방식으로 학습 구간은 폴드가 증가할수록 확장되며, 검증 구간은 그다음 시점의 고정된 구간으로 설정된다. 모델의 평균 성능과 더불어 예측 결과의 일관성과 변동성 및 신뢰도를 확보하기 위해 누적 교차 검증을 기반으로 각 성능 지표에 대한 평균값과 95% 신뢰구간을 산출하였으며, 모델 간 차이의 통계적 유의성을 검증하기 위해 Friedman test 및 사후검정(Nemenyi)을 수행하였다. 사용된 실험은 모두 동일한 환경(Python 3.12.7, Pytorch 2.5.1)에서 수행되었다.
Ⅳ. 실험 결과
4.1 머신러닝 모델 실험 결과
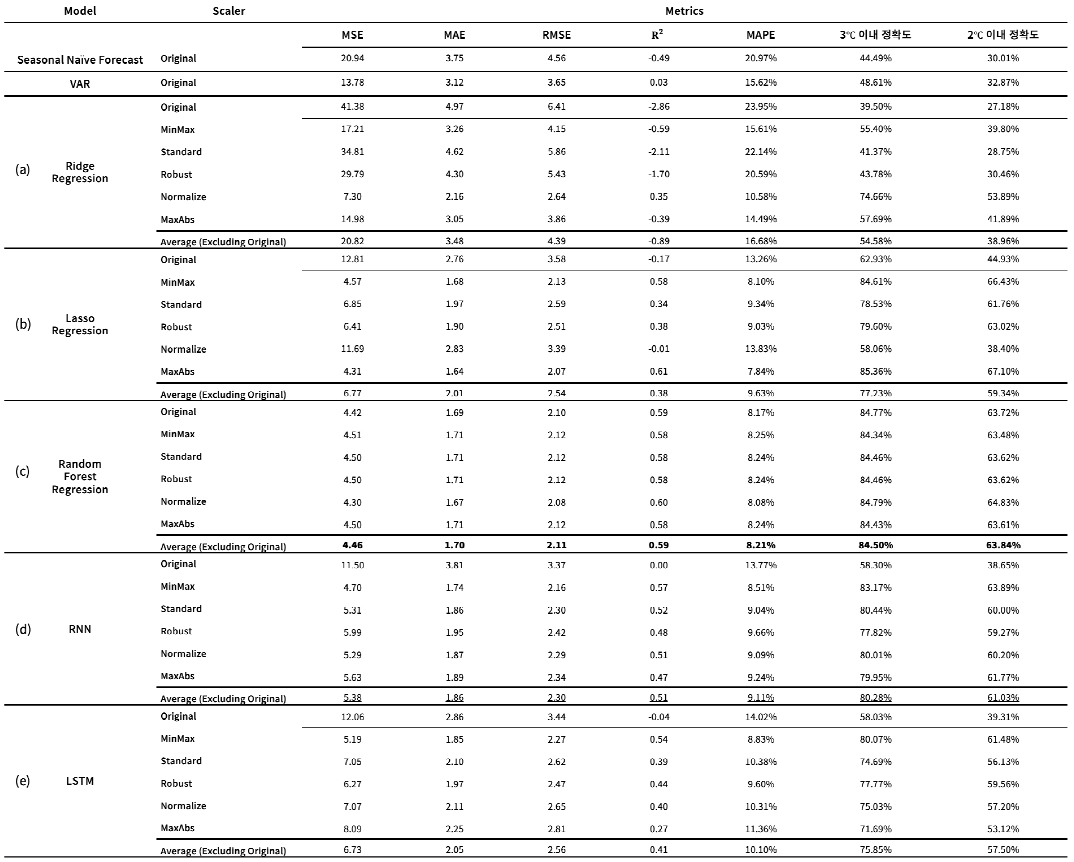
표 2의 (a)에 따르면 릿지 회귀 모델은 전통적 시계열 통계 모델(Seasonal Naive Forecast, VAR)보다 좋은 결과를 보였지만 비교 AI 모델 중 가장 높은 예측 오차(MSE 20.82)와 음수의 R2값을 기록하며, 본 연구 데이터의 비선형성을 효과적으로 학습하지 못하는 한계를 보였다. MAPE는 16.68%, ±3℃ 이내 정확도는 54.58%, ±2℃ 이내 정확도는 38.96%로 전반적으로 예측력이 낮았다. 다만 Normalizer를 적용하면 성능이 소폭 향상되며 ±3℃ 이내 예측 정확도 74.66%, ±2℃ 이내 예측 정확도 53.89%로 개선되었다. Normalizer는 샘플 간 상대적 구조를 유지하면서 값의 크기만 조정하기 때문에, 릿지 회귀의 L2 규제가 과도하게 작용하는 문제를 완화했기 때문이다. 반면 Standard 스케일링 적용 시 가장 낮은 결과를 보였는데, Standard Scaler가 릿지 회귀의 입력 스케일에 따른 규제와 가중치를 강하게 축소하여 결과에 영향을 미친 것으로 분석된다. 그림 3의 (a)에서도 모든 폴드에서 MAPE의 평균이 19.5~22.9%를 보이며, R²는 음수로 나타나 모델이 낮은 예측 성능을 가지고 있음을 보여준다. 그림 4의 (a)에서 예측 추세를 살펴보면 5월과 10월 모두 전반적인 추세와 변동은 잘 따라가지만, 급격한 피크나 단시간 급락 구간에서는 예측값 정밀도가 다소 낮았다. 이는 L2 페널티로 인해 모델의 반응성이 억제된 결과로 해석되며, 예측이 평탄화되는 릿지 회귀 모델의 특성을 잘 보여준다.
Performance results by models

Metrics results based on cross-validation, mean, standard deviation, 95% confidence interval by 5 models

Time series forecast results by model
표 2의 (b)에 따르면 라쏘 회귀 모델은 같은 단순 선형 회귀 모델인 릿지 회귀 모델보다 전반적으로 우수한 성능을 보였다.
모든 평가 지표에서 약 2~3배 이상 높은 성능을 기록했으며 MAPE 9.63%, ±3℃ 이내 예측 정확도 77.23%, ±2℃ 이내 예측 정확도 59.34%로 향상된 성능 결과를 확인할 수 있다. MaxAbs 스케일링을 적용했을 때 가장 좋은 결과를 나타냈는데 이는 MaxAbs가 중심화(Centering) 없이 정규화함으로써 희소성을 그대로 유지하면서 Lasso의 페널티를 공정하게 적용하여 불필요한 특성은 제거하고 중요한 특성만 남겨 해석력이 높였기 때문으로 판단된다. 반면 Normalizer를 적용했을 때는 성능이 저하되었는데, 이는 데이터 중심화 과정을 통해 L1 정규화 효과가 왜곡되었기 때문으로 해석할 수 있다. 그림 3의 (b)에서도 라쏘 회귀가 학습이 진행될수록 같은 선형 회귀 모델인 릿지 회귀 대비 MSE, MAPE가 크게 개선되는 양상을 확인할 수 있다. 그림 4의 (b) 그래프에서 라쏘 회귀가 일정 수준 이상의 추세 재현 능력을 갖추고 있음을 확인시켜 준다. 다만 L1 페널티 탓에 비선형 경계 학습에 한계가 있어 갑작스러운 온도 변화 구간에서는 다소 보수적으로 반응하여 예측 오차가 증가하는 경향이 있는데, 이는 라쏘 회귀 특유의 계수 축소 효과에 기인한 것으로 분석된다.
랜덤 포레스트 회귀는 모든 계절과 도장 위치에서 가장 일관되고 안정적인 예측 성능을 보였다. 표 2의 (c)에 따르면 랜덤 포레스트 회귀는 MSE 4.46, MAE 1.70, RMSE 2.11, MAPE 8.21%, R² 0.59로 예측 설명력이 가장 높았다. 또한 ±3℃ 이내 예측 정확도 84.50%, ±2℃ 이내 예측 정확도 63.84%로 정확도 측면에서도 가장 높았다. 스케일링에 따른 성능 편차는 미미했는데, 랜덤 포레스트 회귀는 트리 기반 구조로 변수의 크기에 민감하지 않기 때문이다. 모든 스케일링 기법에 대해 ±3℃ 이내 예측 정확도는 평균 84%, ±2℃ 이내 예측 정확도는 평균 64%로 고르게 유지되었다. 그림 4의 (c)에서도 랜덤 포레스트 회귀는 예측값이 실제 시계열 온도의 전반적인 흐름과 매우 유사한 추세를 보여주며, 급격한 변화와 패턴도 잘 따라가고 있음을 확인시켜 준다. 이는 랜덤 포레스트 회귀가 단순히 평균값을 예측하는 것이 아니라, 비선형적이고 국소적인 변화를 효과적으로 포착할 수 있음을 의미한다. 다만 그림 3의 (c)를 보면 비교 모델들보다 MAPE의 폴드 간 성능 편차가 큰 편이어서, 폴드 구성에 따라 모델의 예측 신뢰도가 다소 흔들릴 가능성이 있음을 시사한다.
기계학습 기반 모델들은 전통적 시계열 통계 모델(Seasonal Naive Forecast, VAR)보다 전반적으로 더 우수한 예측 성능을 보였다. 전통적인 회귀 기법인 릿지와 라쏘는 변수 간 관계가 단순하고 선형적일 때는 안정적인 성능을 보이지만 데이터가 비선형적이고 복합적인 패턴을 가질수록 중장기 온도 변동을 세밀하게 따라가지 못하고 모든 지표에서 신뢰구간 폭이 크게 나타나 반복 실험 간 예측 변동성이 높다는 한계를 보였다. 반면 랜덤 포레스트 회귀 모델은 가장 높은 예측 정확도와 가장 낮은 오차 지표 결과를 달성했음에도 그림 3의 교차 검증에서 MAPE와 정확도 지표에서 신뢰구간 폭이 크게 나타나 예측 안정성이 충분히 확보지 않은 것으로 나타났다. 즉, 평균 성능은 우수하지만 예측 안정성 측면에서는 다소 취약할 수 있음을 시사한다. 따라서 랜덤 포레스트 회귀는 변수 간 복잡한 상호작용과 비선형성을 사전 가정 없이 학습할 수 있어 시계열 온도 예측에 구조적으로 유리하지만 시점 간 연속성을 명시적으로 모델링하지 않기 때문에 실제 공정에 적용할 경우 시계열 패턴의 장기 추세나 주기성을 완전히 학습하는 데에 제약이 있을 것으로 판단된다.
4.2 딥러닝 모델 실험 결과
표 2의 (d)에서 확인할 수 있듯이 RNN은 머신러닝 기반 회귀 모델보다 높은 정확도를 보였지만 랜덤 포레스트 회귀보다는 성능이 다소 낮았다. 그럼에도 ±3℃ 이내 예측 정확도 80.28%, ±2℃ 이내 예측 정확도 61.03%로 충분히 공정 품질 기준을 충족하고 있음을 보여준다.
스케일링 실험에서 MinMax 스케일링을 적용했을 때 MSE 4.70, MAE 1.74, RMSE 2.16, R² 0.57, MAPE 8.51%, ±3℃ 이내 예측 정확도 83.17%, ±2℃ 이내 예측 정확도 63.89%로 랜덤 포레스트 회귀 모델과 대등한 수준을 달성했다. 이는 입력값이 MinMax 정규화를 거치면서 신경망 활성화 범위 내에 고르게 분포해 급격한 스파이크가 완화되고 RNN의 상태 전이를 한층 안정화한 결과로 해석된다. 반면 Robust 스케일링은 전반적으로 성능이 하락했는데, 이는 Robust 스케일링이 중앙값과 사분위수 범위를 기준으로 하기에 사분위수 범위가 작을 경우 오히려 스케일이 과도하게 해석돼 가중치 업데이트가 불안정해지고 과적합이 발생하면서 오차가 증가한 것으로 판단된다. 그림 3의 (d)를 보면 폴드가 증가할수록 R²가 개선되며 전반적으로 낮은 오차와 안정적인 성능을 유지함을 보여준다. 그림 4의 (d) 역시 RNN이 주요 추세와 구간별 온도 변화를 포착하여 시간 종속적 패턴을 효과적으로 학습한 것을 볼 수 있다. 다만 급격한 진폭 변화 구간에서는 반응 속도가 다소 느려지는 경향이 있는데, 이는 RNN의 특성상 시점 간 정보를 평균화하며 노이즈를 완화하는 과정에서 나타난 현상으로 판단된다.
표 2의 (e)에 따르면 LSTM 모델은 전반적인 평균 수치는 RNN과 유사한 수준이었으나 다소 낮은 정확도 성능과 예측 신뢰도를 보였다. 스케일링 기법에 따른 실험 결과로는 RNN과 같이 MinMax를 적용했을 때 MSE 5.19, MAE 1.85, RMSE 2.27, R² 0.54, ±3℃ 이내 예측 정확도 80.07%, ±2℃ 이내 예측 정확도 61.48%로 성능이 가장 높게 나타났다. MinMax 기법이 LSTM 게이트의 활성화 범위(0-1)에 맞춰 입력값을 고르게 분포시켜 가중치 업데이트를 균등하게 만들고 빠른 수렴과 안정적인 학습 결과를 가능하게 했기 때문으로 해석된다. 반면 MaxAbs 스케일링을 적용했을 때 성능이 가장 저조했는데, 이는 MaxAbs 스케일링이 입력값을 각 특성을 절대 최댓값으로만 나누면 분산이 큰 변수의 영향력이 과도하게 남아 특성 간 불균형이 심화되기 때문으로 보인다. 그림 3의 (e)에서 LSTM은 학습이 진행될수록 RNN보다 MSE, MAE, RMSE가 좀더 빠르게 감소하고 R²가 좀 더 빠르게 상승하는 경향을 보인다.
그림 4의 (e) 역시 LSTM 또한 추세와 구간별 온도 변화를 정확히 추적해 시간 종속적 패턴을 효과적으로 학습했음을 보여준다. 또한 급격한 상승 및 하강 구간에서도 민감하게 반응해 전반적으로 부드러운 예측 곡선을 유지한다.
RNN 모델은 랜덤 포레스트 회귀 모델 다음으로 높은 성능을 기록했으며 그림 3의 (f)에서 RNN과 LSTM은 모든 지표에서 신뢰구간 폭이 가장 작게 나타나 반복 실험 간 일관된 성능을 유지하는 것으로 확인되었다. LSTM은 평균 지표에서 RNN보다 성능이 다소 낮았지만 학습이 진행될수록 MSE, MAE, RMSE 지표에서 성능 격차가 RNN 대비 약 1.5~2배 빠르게 감소하는 양상을 보였다. 이는 데이터가 늘어날수록 LSTM의 성능 개선 여지가 더 높을 가능성을 시사한다. 조선소 도장 품질 관리 및 에너지 효율 측면에서 RNN과 LSTM 모델 모두 현장 요구 수준의 예측 정확도와 오차 범위를 충족한다. 다만 본 연구처럼 데이터 규모가 작고 시퀀스 길이가 짧은 조건에서는 상대적으로 단순한 구조인 RNN이 보다 더 우수한 성능을 보였으나, RNN 특유의 기울기 소실과 장기 의존성 학습 한계를 감안하면 실무 환경에서는 LSTM이 더 적합할 가능성이 높다. 왜냐하면 실제 공정에서는 각 도장 공정에서의 코팅 단계가 수 시간 간격으로 순차적으로 이어지며 선박 규모·기후·교대조 운영 등으로 데이터가 지속적으로 축적되기 때문이다. 아울러 초기 작업 조건이 최종 품질에 영향을 미치는 공정 특성상, 긴 시퀀스를 한 번에 학습할 수 있고 장기 학습 곡선이 더 가파른 LSTM이 정보 소실에 취약한 RNN보다 품질 편차 예측에 유리하다고 판단된다.
4.3 통계적 유의성 검정
그림 5에서 Friedman 검정 결과 모든 지표(MSE, MAE, RMSE, R², MAPE, ±3℃, ±2℃)에서 모델 간 순위 차이가 유의하였으며 (Friedman p < 0.01), Nemenyi 사후검정 결과 RNN은 Ridge 및 Lasso 대비 p < 0.05로 통계적으로 유의하게 우수하였으며, Random Forest와도 MAPE 및 Accuracy 지표에서 유의한 차이를 보였다.

Friedman test(chi-sqaure, p-value) and Nemenyi post-hoc test results
반면 RNN과 LSTM은 모든 지표에서 p > 0.05로 통계적으로 유의한 차이가 없어 동일 성능 그룹으로 분류된다. 이를 종합하면, 제안된 실험에서는 RNN과 LSTM이 통계적으로 최상위 그룹, Random Forest가 중간 그룹, Lasso가 그다음, Ridge가 최하위 그룹으로 구분됨을 확인하였다. 이러한 결과는 평균값만으로 판단했을 때보다 변동성과 신뢰성까지 고려할 때, RNN과 LSTM이 본 연구 데이터셋에서 가장 안정적이고 신뢰도 높은 모델임을 시사한다.
Ⅴ. 결론 및 향후 연구 방향
본 연구에서는 조선소 도장 공정의 온도 예측을 위해 전통적 머신러닝 회귀 모델(Lasso, Ridge), 앙상블 트리 기반 모델(Random Forest Regression), 딥러닝 순환 신경망(RNN, LSTM)을 적용하고 성능을 비교하여 소규모 실측 데이터에서도 효율적으로 공정 온도를 예측할 수 있는지 평가하였다. 평가 기준으로는 모델이 실제 값과 얼마나 근접한 예측을 했는지를 직관적으로 나타내는 MSE, MAE, RMSE, MAPE와 같은 오차 지표와 ±3℃ 이내 정확도, ±2℃ 이내 정확도를 주요 평가 지표로 사용했다. 또한 고비용·고위험 산업인 조선소의 보수적인 운영 환경에서 요구되는 일관성을 보다 정밀하게 평가하고자 누적 평균 교차 검증을 수행하여 각 모델의 성능 판단에 반영하였다.
주요 결과와 시사점은 다음과 같다. 5개의 비교 모델 중 랜덤 포레스트 회귀 모델이 평균 예측 정확도와 오류 지표에서 가장 우수했으나, 폴드 간 MAPE 변동 폭이 상대적으로 커 예측 신뢰도의 안정성이 완전하진 않았다. 다음으로 RNN이 랜덤 포레스트에 근접한 성능을 보이면서도 교차 검증 변동 폭이 작아 산업 현장에서 요구되는 신뢰성을 충족했다. LSTM의 경우 RNN보다 열세했지만, 학습이 진행될수록 격차가 빠르게 축소돼 데이터가 축적될 경우 더 높은 성능 개선의 여지를 보였다. 선형 회귀 계열(릿지·라쏘)은 비선형성이 강한 실제 온도 패턴을 세밀히 추적하지 못했다. 다만 라쏘 회귀는 특성 선택 효과를 통해 릿지보다 나은 성능을 기록하여, 기초 베이스라인으로 활용할 만한 가치가 확인됐다. 스케일링의 영향 측면에서는 딥러닝 계열(RNN·LSTM)은 MinMax, 라쏘 회귀는 MaxAbs, 릿지 회귀는 Normalizer에서 성능이 가장 높았다. 이는 모델별 학습 메커니즘과 입력 분포 간 상호작용이 다르게 작용함을 시사한다. 따라서 도장 공정 데이터 전처리 시 모델 특성을 고려한 맞춤형 스케일링이 필수적이다. 기준치(±3℃ 이내 75% 이상) 충족 모델이 다수 확보돼 도장 품질 관리 시스템에 실시간 경보·스케줄링 기능을 탑재할 수 있다. 특히 RNN, LSTM은 시점 간 연속성을 학습해 급격한 조건 변화에서도 빠르게 적응하므로, 현장 PLC 또는 엣지 디바이스에 배포할 때 높은 실용성이 예상된다. 랜덤 포레스트 회귀는 에너지 절감 파라미터(환기량, 조도) 등과 연계해 의사결정 지원 대시보드에 활용하면 효과적일 것으로 예상한다.
본 연구는 데이터 확보가 어려운 제조 현장에서도 적절한 모델 선택과 전처리만으로 예측 정확도를 확보할 수 있음을 보여주었으며, 기존 연구가 농업, 화학공정, 에너지 저장장치 등 대규모 데이터를 활용한 사례에 집중되어 온 반면, 본 연구는 제한된 관측값만으로도 인공지능 모델이 유의미한 예측 성능을 나타낼 수 있음을 보였다.
향후 연구에서는 장기 데이터를 통합해 학습 곡선을 확장하며, 순환 신경망 계열 알고리즘을 다른 모델과 결합한 혼합형 모델 또는 시계열 패턴을 더 풍부하게 표현할 Transformer 기반 모델을 구축하고 실험을 진행하여 성능을 검증할 계획이다. 본 연구는 제한된 데이터 환경의 조선소 도장 건조 공정에 AI 기반 예측 모델을 적용함으로써 스마트 야드 운영과 에너지 효율화에 실질적 근거를 제공하였으며, 향후 제조업 전반의 공정 자동화와 지능화에도 기여할 수 있을 것으로 기대된다.
Acknowledgments
본 연구는 중소기업기술정보진흥원(TIPA)의 연구비로 수행되었음 (연구번호: RS-2024-00446996)
References
- J.-S. Lee, "Study on Carbon Dioxide Reduction in the Shipbuilding Industry Using an AI-Based Temperature and Humidity Prediction Model" Proc. KIIT Conference, Jeju, Korea, pp. 48, Nov. 2024.
-
H. Bu, Z. Ge, X. Zhu, T. Yang, and H. Zhou, "Prediction of Ship Painting Man-Hours Based on Selective Ensemble Learning", Coatings, Vol. 14, No. 3, Article 318, Mar. 2024.
[https://doi.org/10.3390/coatings14030318]

-
A. Vorkapic, R. Radonja, and S. Martincic-Ipic, "Predicting Seagoing Ship Energy Efficiency from the Operational Data", Sensors, Vol. 21, No. 8, Article 2832, Apr. 2021.
[https://doi.org/10.3390/s21082832]
-
Y. Lee, Y. Choi, H. Cho, and J. Kim, "Prediction of Distillation Column Temperature using Machine Learning and Data Preprocessing", Korean Chem. Eng. Res., Vol. 59, No. 2, pp. 191-199, May 2021.
[https://doi.org/10.9713/kcer.2021.59.2.191]
-
J. Lee, M. Kang, and H. Seo, "Predictive Model of Refrigerating Facilities Temperature in Food Factories Using LSTM", KIISE Trans. Comput. Pract., Vol. 30, No. 2, pp. 91-97, Feb. 2024.
[https://doi.org/10.5626/KTCP.2024.30.2.091]
-
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, "Learning representations by back-propagating errors", Nature, Vol. 323, No. 6088, pp. 533-536, Oct. 1986.
[https://doi.org/10.1038/323533a0]
-
S. Hochreiter and J. Schmidhuber, "Long Short-Term Memory", Neural Computation, Vol. 9, No. 8, pp. 1735-1780, Nov. 1997.
[https://doi.org/10.1162/neco.1997.9.8.1735]
- A. An and D. Kang, "Predicting Summer Temperature using LSTM", Proc. Korea Softw. Congr., pp. 40-42, Dec. 2021.
-
J. Q. Wang, Y. Du, and J. Wang, "LSTM based long-term energy consumption prediction with periodicity", Energy, Vol. 197, Article 117197, Apr. 2020.
[https://doi.org/10.1016/j.energy.2020.117197]
-
J. Song, G. Xue, Y. Ma, H. Li, Y. Pan, and Z. Hao, "An Indoor Temperature Prediction Framework Based on Hierarchical Attention Gated Recurrent Unit Model for Energy Efficient Buildings", IEEE Access, Vol. 7, pp. 157268-157283, Oct. 2019.
[https://doi.org/10.1109/ACCESS.2019.2950341]
-
F. L. Peng, Y. K. Qiao, and C. Yang, "A LSTM-RNN based intelligent control approach for temperature and humidity environment of urban utility tunnels", Heliyon, Vol. 9, No. 2, Article e13182, Feb. 2023.
[https://doi.org/10.1016/j.heliyon.2023.e13182]
-
J. Li, P. Liu, D. Sun, Z. Yan, B. Yu, and L. Zhang, "Time Prediction in Ship Block Manufacturing Based on Transfer Learning", Journal of Marine Science and Engineering, Vol. 12, No. 11, Article 1977, Nov. 2024.
[https://doi.org/10.3390/jmse12111977]
-
J. H. Jeong, J. H. Woo, and J. Park, "Machine Learning Methodology for Management of Shipbuilding Master Data", International Journal of Naval Architecture and Ocean Engineering, Vol. 12, pp. 428-439, 2020.
[https://doi.org/10.1016/j.ijnaoe.2020.03.005]
- J. Jang, "Multivariate Time Series Augmentation for Improving the Performance of Anomaly Detection in Energy System of Ships and Offshore Platforms", M.S. thesis, Dept. of Naval Archit. and Ocean Eng., Seoul Natl. Univ., Seoul, Korea, 2023.

2020년 8월 : 동아대학교 경영학과(학사)
2023년 3월 ~ 현재 : (주)시즌 AI솔루션센터 지능화연구실 실장
관심분야 : AI, 컴퓨터비전, 뇌공학, 산업용 시계열 예측, RAG 챗봇

2016년 2월 : 동국대학교 에너지시스템공학·경제학과(공학사)
2018년 2월 : 세종대학교 기후변화공학과(공학석사)
2016년 2월 ~ 2018년 2월 : (재)기후변화센터 연구원
2020년 12월 ~ 2021년 1월 : 한국과학기술정보연구원(KISTI) 데이터 보조연구원
2021년 4월 ~ 현재 : (주)시즌 기술사업부 부장
관심분야 : AI, 빅데이터 분석, 에너지 효율화, 온실가스 배출계수

2007년 2월 : 울산대학교 조선해양공학과(공학사)
2018년 9월 : 울산대학교 현대중공업 그룹사 단기 MBA
2023년 2월 : 울산과학기술원 기술경영(공학석사)
2007년 2월 ~ 현재 : HD현대중공업 연구원
관심분야 : IoT, 친환경 & 자동화 정비