효율적인 안정성 트레이닝을 위한 병렬 단계적 트레이닝 GAN
 ; 박범찬*
; 양단아*
; Bamchan Park*
; Dana Yang*
; 박범찬*
; 양단아*
; Bamchan Park*
; Dana Yang*
초록
지난 몇 년간, GAN(Generative Adversarial Networks)은 생성 모델 분야에서 다양한 활용을 통해 빠르게 발전해왔다. ProGAN은 생성자와 판별자를 점진적으로 확장하여 고해상도 이미지를 생성하며, SNGAN은 판별자에 스펙트럼 정규화를 적용해 학습 안정성과 성능을 향상시킨다. 본 논문에서는 학습의 불안정성과 이미지 품질을 향상 시키기 위해 생성자와 판별자가 각각의 점진적으로 해상도를 높이고자 한다. 학습이 진행 됨에 따라 모델 구조가 복잡해지는 점진적 학습을 이루며, 두 개의 생성자를 병렬처리 구조의 PS-GAN(Paralled Stepwise Training-GAN)을 제안한다. 실험 결과, 해당 모델은 기존 모델에 비해 생성자와 판별자 간의 학습을 더 빠르고 안정적으로 수렴하였으며 이를 여러 평가지표로 증명하였다. 특히 데이터 품질 지표(FID)에서 SNGAN 대비 약 17.6%, ProGAN 대비 약 5.7% 향상된 결과를 보였으며, 이미지 다양성 지표(IS)에서도 SNGAN보다 약 5.2% 높은 성능을 나타낸다.
Abstract
Generative Adversarial Networks(GANs) have become a key technology in generative modeling, driving advancements across applications. ProGAN demonstrated the benefits of progressively scaling generators and discriminators for high-resolution image generation, while SNGAN improved stability and performance with spectral normalization. However, challenges like training instability, mode collapse, and overfitting persist. This paper introduces Parallel Stepwise Training-GAN(PS-GAN), which progressively increases resolution for both generator and discriminator during training. The dual-generator architecture enables stable, efficient training and adapts to rising complexity. Experimental results show PS-GAN improves FID by 17.6% over SNGAN and 5.7% over ProGAN, with a 5.2% higher IS than SNGAN, demonstrating its effectiveness.
Keywords:
parallel structure generator, progressive step training, training stability, high resolution, convergenceⅠ. 서 론
최근 몇 년간 생성적 적대 신경망(GAN, Generative Adversarial Networks)은 대표적인 생성 모델로서 발전을 이뤄왔다[1]. 2014년 Ian Goodfellow가 GAN을 처음 제안한 이후 GAN은 이미지, 동영상, 텍스트 등의 다양한 데이터 형식에서 새로운 데이터를 생성하는 능력을 보여주며 많은 연구가 이루어졌다. GAN은 두 개의 신경망, 즉 생성자(Generator)와 판별자(Discriminator)로 구성된다. 이들은 서로 경쟁하며 학습한다. 생성자는 가능한 실제와 같은 데이터를 생성하며, 판별자는 이러한 데이터를 진짜와 가짜로 구분하려 한다[2].
GAN은 다양한 도메인에서 활용되기 위해 지금까지 발전해 왔다. 그 중 대표적으로 모델의 네트워크 개선이 있다. DCGAN(Deep Convolutional GAN) 및 ProGAN, StyleGAN은 컨볼루션 신경망을 바탕으로 각각 해결하고자 하는 문제에 따라 네트워크를 개선하였다. ProGAN(Progressive Growing of GANs)은 생성자와 판별자를 점진적으로 확장하는 방식을 도입하여 고해상도 이미지 생성에서 큰 성과를 거두었다[3]-[5]. 또한, SNGAN(Spectral Normalization GAN)은 판별자의 안정성을 높이기 위해 스펙트럼 정규화를 도입하여, 학습 과정에서의 안정성을 강화하고 더 나은 성능을 달성하였다[6]. 이처럼 GAN 모델의 발전은 이미지 생성 성능 및 생성 이미지의 다양성을 지속적으로 향상시켜왔다. 이와 더불어, 학습 구조의 개선 및 변형으로 학습의 성능을 향상시켰다. WGAN(Wasserstein GAN)은 Wasserstein 거리 개념을 도입하여 학습 과정의 불안정성을 해결하고, 보다 안정적인 학습을 가능하게 했다[7]. GAN은 이미지 생성뿐만 아니라 이미지 변환, 스타일 전이, 텍스트 생성 등 다양한 분야에서 활용된다[8].
그럼에도 불구하고, GAN은 여전히 다음과 같은 한계점을 가지고 있다.
- 1. 훈련 불안정성: GAN의 훈련 과정에서 생성자와 판별자 간 균형이 무너질 수 있으며, 이로인해 모드 붕괴(Mode Collapse) 문제가 발생한다. 이는 생성자가 다양성을 잃고 특정 데이터만 생성하는 경향이 나타날 수 있다[9].
- 2. 과적합 문제: 모델의 복잡성과 불안정한 학습으로 인해 과적합(Overfitting)이 발생할 가능성이 높다[9].
- 3. 이미지 품질의 한계: 고해상도 이미지 생성에는 비교적 많은 세부 정보를 포함한 복잡한 생성자 구조가 필요하며 이러한 구조는 학습하는 과정에서 시간과 비용이 과도하게 소모된다[10].
이와 같이 GAN은 여전히 고해상도의 이미지를 현실감 있게 생성하는 데 한계를 보이고 있다. 이러한 문제를 해결하기 위해 본 논문에서는 PS-GAN(Paralled Stepwise Training GAN)을 제안한다. PS-GAN은 생성자 네트워크의 병렬처리를 통해 훈련 불안정성과 과적합 문제를 완화하며 점진적 단계 학습과정을 통해 이미지 품질의 향상을 보인다. 본 논문의 유효성 평가를 위해 타 모델과의 손실(Loss)에 대한 지표와 생성한 이미지를 비교한다. 또한, 생성된 이미지와 실제 이미지 간의 분포 차이를 측정한 지표 FID(Fréchet Inception Distance)와 생성된 이미지의 다양성과 품질을 정량화한 지표 IS(Inception Score)를 통해 해당 모델의 유효성을 증명한다.
본 논문의 구성은 다음과 같다. 2장에서 관련 연구로 SNGAN과 ProGAN에 대해 설명하고 3장에서는 생성자의 병렬처리와 점진적 단계 학습의 제안 메커니즘을 제시한다. 4장 실험 결과를 통해 제안 모델의 성능을 평가하며 5장에서 결론을 맺는다.
II. 관련 연구
2.1 SNGAN
GAN은 생성자와 판별자로 구성된 두 개의 신경망이 경쟁적으로 학습하는 구조를 통해 데이터를 생성한다. 생성자는 실제 데이터와 유사한 데이터를 생성하는 역할을 하고, 판별자는 생성자가 만든 데이터를 실제 데이터와 구별하는 역할을 한다. 하지만 이러한 학습 구조는 훈련 과정에서 불안정성과 모드 붕괴, 과적합 문제를 야기할 수 있다[8][9].
이를 해결하기 위해 Miyato는 2018년에 판별자 네트워크의 각 레이어에 스펙트럴 정규화(SN, Spectral Normalization)를 적용한 SNGAN을 제안하였다[10].
SN은 각 레이어의 가중치 행렬의 가장 큰 특이값을 사용하여 가중치를 정규화함으로써 판별자의 립시츠 상수를 제한한다. 이로 인해 판별자는 더 안정적으로 기울기를 전파하며 학습 과정에서 발생할 수 있는 기울기 소실을 방지할 수 있다. 그림 1은 SNGAN의 구조를 시각화한다. 생성자는 기본적인 GAN과 유사한 구조를 가지며, 랜덤한 노이즈 벡터를 입력받아 업 샘플링과 합성곱 연산을 통해 데이터를 생성한다. 판별자는 실제 데이터와 생성된 데이터를 입력받아 진위여부를 판별하며, SN을 통해 안정적으로 학습한다. 이 과정에서 판별자는 입력 데이터의 진위를 이진 출력으로 나타내고, 손실 함수와 역전파를 통해 성능을 개선한다.

SNGAN architecture
SN은 가중치 행렬의 스펙트럴 정규화를 계산하여 판별자의 변화를 제한함으로써 훈련의 안정성을 높인다. 그러나 이러한 스펙트럴 연산은 추가적인 자원을 요구하며, 특히 대규모 신경망에서는 계산 비용이 증가한다. SN의 실행은 가중치 행렬의 가장 큰 특이값을 반복적으로 계산하는 과정을 포함하며, 이는 Power Iteration 알고리즘 등을 사용하여 수행된다. 네트워크의 각 레이어에서 이러한 연산을 반복해야 하므로 계산 비용이 기하급수적으로 증가하며, 대규모 데이터 셋과 복잡한 모델에서는 효율성을 제한할 수 있다. 이로 인해 정규화 기법이 판별자의 구별 능력을 제한하고, 전반적인 이미지 품질에 부정적인 영향을 미칠 수 있다[11]. 결국, SNGAN의 SN은 훈련의 안정성을 보장하지만 계산 비용의 증가라는 문제점을 동반한다. SNGAN과 관련 연구는 고해상도 출력과 업 스케일링에 대한 연구로 발전하고 있지만, 학습의 불안정성과 과적합 문제는 여전히 존재한다[11].
본 논문에서는 훈련 안정성을 위한 SNGAN의 SN 패널티가 아닌, 생성자 기반의 병렬구조를 사용하여 판별자에게 패널티를 부여한다. 이를 통해 불안정한 학습을 완화하고 과적합 문제를 해결하고자 한다.
2.2 ProGAN
GAN의 한계 중 하나는 고해상도 이미지를 생성하는 데 어려움을 겪는다는 점이다. GAN이 고해상도 이미지를 생성하려면 생성자와 판별자의 네트워크가 더 복잡해진다. 그로 인해 훈련이 불안정해지며 많은 자원이 요구된다. 이러한 문제를 해결하기 위해 Karras는 2017년에 ProGAN을 제안하였다[4]. ProGAN은 고해상도 이미지 생성을 위한 학습 방법으로 점진적인 네트워크 구조 성장을 통해 훈련 불안정성을 해결하고, 고해상도 이미지를 생성한다.
ProGAN의 제안 방법은 생성자와 판별자의 네트워크가 처음부터 복잡한 구조를 가지지 않고, 저해상도 이미지로부터 시작하여 점차 고해상도로 확장해 나가는 방식이다. 초기에는 4x4와 같은 작은 해상도에서 학습을 시작하고, 이후 점진적으로 그림 2와 같이 네트워크에 레이어를 추가하여 해상도를 증가시킨다. 이 과정에서 각 단계에서 네트워크는 점차 더 높은 해상도의 세부 정보를 학습하게 된다. 이는 고해상도 이미지에서 발생할 수 있는 훈련의 불안정성을 완화한다. ProGAN의 장점은 이러한 점진적 학습을 통해 고해상도 이미지를 보다 안정적으로 생성할 수 있다는 점이다.

ProGAN progressive learning process
네트워크가 초기 단계에서 간단한 구조로 시작하기 때문에 복잡한 고해상도 이미지를 처음부터 생성하려는 기존 방식보다 학습 과정이 더 안정적이다. 또한, 점진적 학습은 고해상도 이미지를 생성하는 데 필요한 세부 정보를 네트워크가 단계적으로 학습한다. 이를 통해 이미지 품질을 높이는 데 기여한다[4].
하지만 ProGAN에도 몇 가지 단점이 존재한다. 먼저, 점진적 학습 과정은 각 단계별로 고해상도 이미지를 학습해야 하므로 훈련 시간이 길어질 수 있다. 또한, 모든 단계에서 네트워크의 구조가 변화한다. 이는 학습을 재설계하고 최적화하는 데 추가적인 노력이 필요하다. 마지막으로, 여전히 고해상도 이미지에서 모드 붕괴 문제가 발생할 수 있다[12]. 결론적으로, ProGAN은 고해상도 이미지 생성에 있어 GAN이 더욱 안정적이고 효과적으로 학습할 수 있는 방법을 제시하였다. 그러나 여전히 고해상도 이미지 생성에서 발생하는 과적합 문제와 긴 훈련 시간은 해결해야 할 과제로 남아있다. 본 논문에서는 ProGAN의 점진적 학습 방식을 발전시켜 PS-GAN에서 생성자의 병렬처리와 결합함으로써 훈련 시간을 줄이고, 고해상도 이미지 생성의 효율성을 향상시키고자 한다.
III. 제안하는 생성 적대 네트워크 모델 구조 및 기법
3.1 생성자 병렬처리 구조
PS-GAN은 과적합 및 훈련 불안정성 문제를 완화하기 위해 새로운 접근 방식을 제안한다. PS-GAN은 생성자의 병렬처리를 통해 두 개의 독립적인 생성자가 생성한 데이터를 판별자에 전달한다. 그리고 두 개의 생성자의 손실을 평균화하는 방식으로 GAN의 일반적인 학습의 불안정성을 해결한다. 따라서, 판별자에 직접적인 제약 없이 각 네트워크 간의 수렴 속도를 빠르고 안정적인 학습으로 유도하여 모드 붕괴와 과적합 문제를 해결할 수 있다[13].
그림 3과 같이 PS-GAN 구조는 생성자를 G1, G2와 같이 병렬 구조를 통하여 학습을 진행한다. 이 두 독립적인 생성기는 각각 다른 가짜 데이터를 생성하며, 이 데이터들은 실제 데이터 x와 함께 판별자에 입력된다. 기존 GAN에서 판별자는 실제 데이터와 가짜 데이터를 이진 분류하는 반면, PS-GAN의 판별자는 세 개의 데이터를 받는다. 판별자는 세 데이터 중 한 데이터만을 실제로 분류하며 나머지 두 데이터를 가짜로 분류한다. 해당 방식을 통해 PS-GAN은 정규화 없이도 판별자가 생성자보다 더 빠르게 학습하는 문제를 개선할 수 있다.

PS-GAN architecture
PS-GAN 모델은 판별자가 처리하는 데이터가 세 개이기 때문에 손실 계산 방식이 기존 GAN과 다르다. 두 개의 가짜 데이터가 포함됨으로써 각 훈련 반복마다 두 번의 손실 값 갱신이 발생한다. 이러한 평균 손실 계산 방식을 통해 G1과 G2가 균형적으로 학습되도록 하여 손실 함수의 변동성을 줄이고, 이를 통해 학습 안정성을 개선한다. 이는 각 학습 단계에서 발생하는 오차를 더 일관되게 반영함으로써 이루어지며 생성자와 판별자 간의 수렴 속도를 증진시켜 생성 데이터의 품질을 높이는 데 기여한다[13].
이와 같이, PS-GAN 모델은 두 개의 독립적인 생성자를 사용함으로써 판별자의 과도한 학습을 조절하고 모드 붕괴 및 과적합 문제를 완화한다. 또한, 평균 손실 계산 방식은 각 생성자가 발생시키는 오차를 균형 있게 반영하여 손실 함수의 변동성을 줄이고, 이를 통해 전체 모델의 학습 과정을 안정화한다. 이러한 접근 방식은 생성자와 판별자 간의 학습 속도 차이를 줄이면서 안정적인 학습으로 학습의 불안정성을 완화한다[14].
3.2 점진적 단계 학습
본 논문에서는 그림 3에서 볼 수 있는 바와 같이 새로운 점진적 단계 학습 PS-GAN을 제안한다. ProGAN은 초기 단계에서 새로운 레이어를 추가하는 점진적 학습을 하였다. 그러나 학습이 진행됨에 따라 안정적이지 않다. 또한, 총 학습의 시간이 기존 GAN과 달리 오래 걸리는 문제가 존재한다. 제안하는 PS-GAN은 더 빠른 안정적인 학습을 위해 일정 학습 횟수(epoch)에 도달할 때마다 생성자(G)와 판별자(D)의 구조를 단계적으로 변경하여 학습을 진행한다. PS-GAN은 다음과 같은 방식으로 진행된다. 초기에는 간단한 모델 생성자(G0)와 판별자(D0)를 사용하여 학습을 시작한다. 일정 학습 횟수에 도달하면 초기에 사용한 모델보다 조금 더 복잡한 생성자(G1)와 판별자(D1) 모델로 변경된다. 후에 다시 일정 학습 횟수에 도달하면 이전 모델보다 더 복잡한 생성자(G2)와 판별자(D2)로 변경하여 더 복잡한 학습을 진행할 수 있는 점진적 단계 학습을 거치게 된다. 각각의 모델 G0, G1, G2, D0, D1, D2의 레이어 해상도는 학습하는 데이터에 따라 달라질 수 있다.
이러한 과정은 저해상도 이미지 특징부터 학습하여 고해상도의 특징까지 안정적으로 학습된다. GAN에서 문제점으로 지적되는 이미지 왜곡 문제를 효과적으로 해결한다.
3.3 가중치 전이 메커니즘
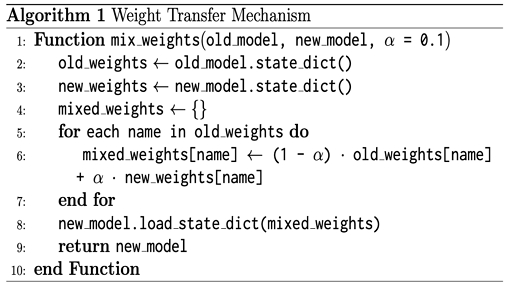
기존 ProGAN의 점진적 학습에서는 초기 단계 레이어에서 새로운 레이어를 추가하여 해상도를 점차 높일 때 가중치를 선형적으로 혼합하였다. 본 논문에서 제안하는 PS-GAN은 일정 학습 횟수가 지남에 따라 더 복잡한 모델로 점진적 단계 학습이 진행된다. 이러한 학습은 저해상도의 이미지 특징부터 학습하게 된다. 복잡한 모델로 점진적 단계 학습 시 기존에 학습된 저해상도 이미지 특징의 데이터를 보존하기 위하여 이전 가중치 정보를 조절하며 비중을 두는 "MIX_WEIGHTS" 함수를 사용하였다.
알고리즘 1에서는 가중치 전이 메커니즘을 구현하는 방법을 설명한다. 초기 모델(old_model)과 더 복잡한 새로운 모델(new_model)의 가중치를 각각 old_weight와 new_weights에 저장한다. 이어서, 모든 가중치에 대해 초기 모델의 가중치(old_weight)와 새로운 모델의 가중치(new_weights)를 혼합하여 m.weights(mix_weights)를 생성한다. 알고리즘 1에서 α는 GAN 모델의 학습 가중치를 조절하는 하이퍼파라미터(Hyperparameters)로 초기 모델과 이후 모델의 가중치 혼합 비율을 α로 조절할 수 있으며 α 값은 0과 1 사이의 값으로 설정한다. 마지막으로 혼합된 가중치를 새로운 모델에 불러서 업그레이드된 모델을 반환한다.

Weight transfer mechanism
본 논문에서는 α값을 0.1로 하여 이전 초기 모델의 저 해상도 이미지 특징을 더 크게 활용하는 안정적인 학습을 통해 이미지 해상도 향상과 기존 GAN 문제로 여겨지는 이미지 왜곡 문제를 해결하고자 하였다.
3.4 손실 함수
PS-GAN은 기존 GAN의 Loss 형태와 방식이 다르다. GAN의 판별자는 Loss를 업데이트할 때, 두 데이터에 대한 이진 분류를 한다. 하지만 PS-GAN은 판별자에 할당되는 데이터가 총 세 개이며 데이터를 넘김에 따라 거짓으로 분류된 데이터가 두 개 생성되는 구조를 지닌다. 그러므로 손실은 총 두 번 발생하게 된다. 판별자 분류에 따른 손실값 갱신에 대한 경우는 다음과 알고리즘 2과 같다.
Update loss value
해당 평균 손실 계산 방식을 통해 G1과 G2가 균일한 학습을 하도록 하여 손실의 변동을 줄임으로 학습의 안정성을 증진한다.
안정화된 학습을 통해 모델이 데이터의 다양한 특성을 효과적으로 학습하여 적용하고 이를 바탕으로 더 정확한 예측을 수행할 수 있다. 또한, 생성자와 판별자 간의 수렴 속도를 앞당겨 각 네트워크 간의 균일한 학습을 기대할 수 있다. 결과적으로, GAN이 가지고 있던 훈련 불안정성과 과적합 문제는 판별자의 간접적인 제약을 통해 빠른 수렴 속도를 이뤄내어 개선한다.
Ⅳ. 실험 결과
본 논문에서 제안하는 PS-GAN 모델을 학습 당 생성자와 판별자의 손실값을 통해 학습의 불안정성과 과적합에 이점이 있음을 보이며, 생성한 이미지와 FID, IS를 통해 품질의 향상과 다양함을 증명한다.
4.1 실험 환경
본 논문에서 제안하는 모델은 Windows 10 운영 체제와 AMD Ryzen CPU를 사용한다. 또한, 복잡한 그래픽 처리와 딥러닝 연산을 위해 GPU와 대규모 데이터셋을 처리하기 위한 RAM을 시뮬레이션 환경으로 사용한다.
Experimental environment
본 실험에서는 MNIST 데이터셋을 사용하여 모델의 성능을 평가하였다. MNIST는 28×28 픽셀의 흑백 손글씨 숫자 이미지로 구성되며, 숫자 0에서 9까지의 총 10개의 클래스가 포함되어 있다. 각각의 클래스는 6만 개의 훈련 이미지와 1만 개의 테스트 이미지로 구성되어 있으며, 모델 학습과 평가에 이상적인 표준 데이터셋이다[15].
모델 학습은 MNIST 데이터셋의 전체 훈련 세트를 사용하였으며, 실험은 PyTorch 프레임워크를 기반으로 진행되었다. 각 이미지는 [0, 1] 범위로 정규화되었으며, 학습 과정에서는 배치 크기를 64로 설정하여 네트워크를 훈련시켰다.
4.2 손실값 비교
그림 4~6은 각각 SNGAN, ProGAN, PS-GAN의 생성자와 판별자의 학습 당 평균 손실값을 시각화 하여 나타낸다. 각 모델의 성능을 비교하기 위해 손실값의 변동과 안정성, 최종 수렴 여부를 평가할 수 있다[16].
그림 4 SNGAN은 초기 손실값 변동이 큰 폭을 보였으나, 학습이 진행됨에 따라 판별자와 생성자 손실값이 점차 안정화되었다. 그러나 생성자와 판별자의 손실값 차이가 약 1.0 정도를 유지하는 것을 보아 불안정한 학습이 진행되며 수렴하지 못함을 보여준다.

Average loss in SNGAN
그림 5 ProGAN은 비교적 일정한 손실값을 유지하며, 초기부터 판별자와 생성자가 유사한 수준의 손실값으로 시작하여 학습이 진행됨에 따라 서서히 안정화되었다. 특히, ProGAN은 중간 학습 구간에서 손실값의 차이가 거의 일정하게 유지되며 모델이 훈련 초기부터 안정적인 학습을 보이는 것이 특징이다. 그러나 생성자와 판별자의 손실값 진행폭이 일정하지 못함을 볼 수 있다. 이는 안정적으로 학습이 수렴되지 않음을 알 수 있다[17].

Average loss in ProGAN
제안 모델인 그림 6 PS-GAN은 약 50 학습 이후부터 판별자와 생성자의 손실값 차이가 비교적 일정하게 감소한다. 이는 PS-GAN이 판별자와 생성자의 균형을 맞추어 학습하고 있음을 보여준다[18]. 또한, 두 개의 생성자(G1, G2)의 손실값이 각각 수렴하며, 판별자가 여러 형태의 손실에도 효과적으로 판별하고 있음을 알 수 있다. 이는 이전 모델들보다 이미지 생성 능력의 향상에 기여한다[14].

Average loss in PS-GAN
결과적으로, PS-GAN은 SNGAN 및 ProGAN보다 안정적인 손실값 수렴을 보여주었다. 이는 안정적인 학습으로 과적합을 방지하고 생성 이미지의 품질을 향상시킨다[19].
4.3 생성자 데이터 비교
그림 7~9은 각각 SNGAN, ProGAN, PS-GAN 모델을 통해 생성된 MNIST 이미지이다. 각 이미지를 비교하였을 때 SNGAN의 생성 이미지는 이미지 품질이 다소 부족함을 육안으로 판단할 수 있다. ProGAN과 PS-GAN의 생성 이미지는 품질이 비교적 우수하나 PS-GAN의 이미지 품질이 윤곽의 표현이나 텍스트 선명도가 조금 더 좋은 것을 확인할 수 있다.

Generated image by SNGAN

Generated image by ProGAN

Generated image by PS-GAN
4.4 FID와 IS 비교
본 실험에서는 제안된 PS-GAN의 성능을 평가하기 위해 FID와 IS를 사용하여 SNGAN, ProGAN과 비교하였다. FID는 생성된 이미지와 실제 이미지 간의 통계적 차이를 측정한다. FID 값이 낮을수록 생성된 이미지가 실제 이미지에 가까움을 의미한다[20].
반면 IS는 생성된 이미지의 다양성과 품질을 종합적으로 평가하는 지표이다. 값이 높을수록 더 다양한 고품질의 이미지를 생성했음을 나타낸다[21].
표 2에 기재된 바와 같이 FID 값은 SNGAN, ProGAN, PS-GAN 순으로 각각 8.34, 7.29, 6.87로 나타난다. PS-GAN은 SNGAN과 ProGAN에 비해 가장 낮은 FID 값을 기록하였으며, 이는 PS-GAN이 상대적으로 더 실제와 유사한 이미지를 생성했음을 알 수 있다. 특히, ProGAN과 비교했을 때 0.42 차이로 우수한 성능을 보여주었는데, 이는 제안된 PS-GAN의 이미지 품질 향상을 알 수 있다. IS의 경우 ProGAN이 12.7로 가장 높은 점수를 기록하였고, PS-GAN이 그 뒤를 이어 12.2를 측정한다. SNGAN은 11.6으로 가장 낮은 IS 값을 나타낸다. 이는 ProGAN과 PS-GAN이 상대적으로 더 다양한 이미지를 생성하는 데 성공했음을 의미한다[21]. PS-GAN은 다소 ProGAN에 비해 낮은 IS 값을 보인다. 그러나 SNGAN보다 높은 성능을 나타내며, FID 값에서의 우수한 성능과 결합하여 PS-GAN이 실제와 유사하면서도 다양한 이미지를 생성할 수 있음을 증명한다.
Comparison of FID and IS by models
결과적으로, PS-GAN은 SNGAN 및 ProGAN에 비해 FID와 IS 지표에서 전반적으로 더 우수한 성능을 보였다. 특히 FID에서 가장 낮은 값을 기록한 것은 생성 이미지의 품질이 실제와 매우 유사함을 나타낸다[20]. 이는 제안된 PS-GAN 모델이 안정적이고 신뢰성 있는 이미지를 생성할 수 있음을 알 수 있다. IS 점수에서는 ProGAN보다 조금 낮았지만 여전히 경쟁력 있는 성능을 유지하였으며, 전반적으로 균형 잡힌 성능을 보였다. 이러한 결과는 제안하는 PS-GAN이 기존 모델보다 안정적인 학습으로 이미지 품질을 향상함을 증명한다.
4.5 시간 비용 비교
다음 표 3에서는 SNGAN을 상대 시간비의 기준으로, ProGAN, 그리고 PS-GAN의 다양한 구성에서의 학습 시간 비용을 비교·분석한다. 특히, SNGAN의 스펙트럴 노멀라이제이션(SN) 패널티 제거, PS-GAN의 생성자 수 증가와 같은 변형이 시간 비용에 미치는 영향을 평가하여 효율성과 성능 간의 관계를 실험하였다.
Comparison of time cost by models
SNGAN은 판별자의 스펙트럴 노멀라이제이션(SN) 적용으로 3920초가 소요되었다. SN 패널티를 제거하고 생성자 수를 2개로 늘린 변형 SNGAN은 3506초로 약 10.6% 시간 단축이 이루어졌다. ProGAN은 점진적 레이어 확장으로 인해 5277초가 소요되었다. 이는 계산량 증가로 SNGAN보다 34.6% 더 많은 시간이 필요했다. 반면 PS-GAN은 점진적 단계 학습을 적용하여 생성자 1개 기준 3780초로 ProGAN 대비 약 28% 시간 단축을 보였다. 생성자 수를 늘릴수록 학습 시간은 선형적으로 증가하여 생성자 2개일 때 4850초, 3개일 때 6214초로 각각 28%씩 추가 증가하였다. 이는 판별자의 연산 부담 증가와 손실 평균화 과정으로 인한 비용 상승이다. 결과적으로, SN 패널티는 학습 안정성을 제공하지만 시간 비용이 성능 대비 크다.
ProGAN은 고해상도 이미지 생성이 가능하지만 시간 비용이 크다. PS-GAN은 생성된 이미지 성능의 향상 대비 사용되는 시간 비용이 SNGAN과 ProGAN의 성능 대비 시간 비용보다 효율적임을 알 수 있다.
4.6 생성자 개수에 따른 성능 비교
표 4는 생성자가 추가됨에 따른 성능 지표이다. PS-GAN의 생성자 2개의 병렬 처리 구조를 기준으로 상대 시간비를 기준하였으며, 생성자 개수의 증가에 따른 FID, IS의 수치를 비교하였다. 생성자 개수가 증가함에 따라 PS-GAN의 학습 시간은 선형적으로 증가했으나 이미지 품질과 다양성은 개선되었다. 학습 시간은 생성자 1개일 때 3784초(78%), 2개일 때 4851초(100%), 3개일 때 6214초(128%)로 증가하였다. 이는 판별자가 처리해야 할 가짜 데이터의 양과 손실 평균화 연산이 추가되었기 때문이다. FID는 생성자 1개에서 7.15 ± 0.03, 2개에서 6.87 ± 0.02, 3개에서 6.68 ± 0.03으로 감소하여 이미지 품질이 점진적으로 향상되었다. IS 역시 1개에서 11.9 ± 0.04, 2개에서 12.2 ± 0.05, 3개에서 12.7 ± 0.05로 증가해 이미지 다양성과 품질이 개선됨을 확인하였다. 결과적으로 생성자 수를 늘리면 성능이 개선되지만 학습 시간이 증가한다. 따라서, 시간 비용과 성능 개선의 트레이드오프를 고려하여 실용적인 환경에 맞게 생성자 수를 조절하는 것이 필요하다.
Performance evaluation according to the number of the generators of PS-GAN
Ⅴ. 결론 및 향후 과제
GAN은 대표적인 생성 모델로서 급격한 발전을 이뤄왔지만 그 한계는 명확했다. 훈련 불안정성, 과적합 문제와 더불어 고화질에서의 품질 저하에 관한 문제는 지난 몇 년간 계속해서 지적되었다. 본 논문에서는 생성자와 판별자 간의 균형과 품질의 향상을 위하여 점진적 단계 학습과 생성자 병렬처리 구로를 통한 새로운 알고리즘은 제안하였다. 이러한 해당 모델 구조는 타 모델과 비교했을 때 과적합과 불안정한 학습을 감소하는데 효과가 있었으며, 데이터의 품질을 향상하는데 기여함을 실험을 통해 확인 할 수 있었다.
이러한 새로운 패러다임은 앞으로 GAN을 포함한 생성 모델의 발전에 기여할 것이며 의료, 컴퓨터 비전, 음성, 음악, 텍스트 등 다양한 분야에 더욱 적용과 활용이 가능할 것이다[22]-[24]. 향후 연구에서는 모델 간의 수렴 속도를 더 높이고, 다양한 분야의 데이터셋에서 초고해상도 데이터의 품질을 개선하는 시스템을 발전시킬 것이다.
Acknowledgments
이 논문은 2024학년도 한국성서대학교 대학혁신지원사업의 지원을 받아 수행된 연구임
References
-
T. Chakraborty, U. Reddy K S, S. M. Naik, M. Panja, and B. Manvitha, "Ten years of Generative Adversarial Nets (GANs): A survey of the state-of-the-art", arXiv preprint, arXiv:2308.16316, , Aug. 2023.
[https://doi.org/10.48550/arXiv.2308.16316]

- I. J. Goodfellow, et al., "Generative adversarial nets", NIPS'14: Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal Canada, Vol. 2, pp. 2672-2680, Dec. 2014.
-
A. Radford, L. Metz, and S. Chintala, "Unsupervised representation learning with deep convolutional generative adversarial networks", arXiv preprint, arXiv:1511.06434, , Nov. 2015.
[https://doi.org/10.48550/arXiv.1511.06434]
-
T. Karras, T. Aila, S. Laine, and J. Lehtinen, "Progressive growing of GANs for improved quality, stability, and variation", arXiv preprint, arXiv:1710.10196, , Oct. 2017.
[https://doi.org/10.48550/arXiv.1710.10196]
-
T. Karras, S. Laine, and T. Aila, "A style-based generator architecture for generative adversarial networks", Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp. 4401-4410, Jun. 2019.
[https://doi.org/10.1109/CVPR.2019.00453]
-
T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, "Spectral normalization for generative adversarial networks", arXiv preprint arXiv:1802.05957, , Feb. 2018.
[https://doi.org/10.48550/arXiv.1802.05957]
-
M. Arjovsky, S. Chintala, and L. Bottou, "Wasserstein GAN", arXiv preprint, arXiv:1701.07875, , Jan. 2017.
[https://doi.org/10.48550/arXiv.1701.07875]
-
P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, "Image-to-image translation with conditional adversarial networks", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, pp. 5967-5976, Jul. 2017.
[https://doi.org/10.1109/CVPR.2017.632]
-
R. Durall, A. Chatzimichailidis, P. Labus, and J. Keuper, "Combating mode collapse in GAN training: An empirical analysis using Hessian eigenvalues", arXiv preprint, arXiv:2012.09673, , Dec. 2020.
[https://doi.org/10.48550/arXiv.2012.09673]
-
T. Karras, M. Aittala, T. Aila, and S. Laine, "Elucidating the design space of diffusion-based generative models", arXiv preprint,, arXiv:2206.00364, , Jun. 2022.
[https://doi.org/10.48550/arXiv.2206.00364]
-
Z. Li, M. Usman, R. Tao, P. Xia, C. Wang, H. Chen, and B. Li, "A Systematic Survey of Regularization and Normalization in GANs," arXiv preprint, arXiv:2008.08930, , Aug. 2020.
[https://doi.org/10.48550/arXiv.2008.08930]
- A. Brock, J. Donahue, and K. Simonyan, "Large scale GAN training for high fidelity natural image synthesis", International Conference on Learning Representations (ICLR), New Orleans, USA, Apr. 2019.
- Q. Hoang, T. D. Nguyen, T. Le, and D. Phung, "Multi-Generator Generative Adversarial Nets", arXiv preprint arXiv:1708.02556, , Aug. 2017. https://arxiv.org/abs/1708.02556, .
-
X. Wang, "Shared loss between generators of GANs", arXiv preprint, arXiv:2211.07234, , Nov. 2022.
[https://doi.org/10.48550/arXiv.2211.07234]
-
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, "Gradient-based learning applied to document recognition", Proceedings of the IEEE, Vol. 86, No. 11, pp. 2278-2324, Nov. 1998.
[https://doi.org/10.1109/5.726791]
- L. Mescheder, A. Geiger, and S. Nowozin, "Which training methods for GANs do actually converge?", Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, Vol. 80, pp. 3481-3490, Jul. 2018.
-
I. Yahiro, T. Ishida, and N. Yokoya, "Flooding regularization for stable training of generative adversarial networks", arXiv preprint, arXiv:2311.00318, , Nov. 2023.
[https://doi.org/10.48550/arXiv.2311.00318]
-
T. Chen, X. Zhai, M. Ritter, M. Lucic, and N. Houlsby, "Self-supervised GANs via auxiliary rotation loss", arXiv preprint, arXiv:1811.11212, , Nov. 2018.
[https://doi.org/10.48550/arXiv.1811.11212]
-
C. Saharia, et al., "Photorealistic text-to-image diffusion models with deep language understanding", arXiv preprint, arXiv:2205.11487, , May 2022.
[https://doi.org/10.48550/arXiv.2205.11487]
- M. Heusel, H. Ramsauer, T. Unterthiner, and B. Nessler, S. Hochreiter, "GANs trained by a two time-scale update rule converge to a local Nash equilibrium", Advances in Neural Information Processing Systems, Long Beach California USA, Vol. 30, pp. 6629-6640, Dec. 2017.
- T. Salimans, I. Goodfellow, and W. Zaremba, "Improved techniques for training GANs", Advances in Neural Information Processing Systems, Barcelona, Spain, Vol. 29, pp. 2234-2242, Dec. 2016.
-
P. S. Paladugu, et al., "Generative adversarial networks in medicine: Important considerations for this emerging innovation in artificial intelligence", Annals of Biomedical Engineering, Vol. 51, No. 10, pp. 2130-2142, Oct. 2023.
[https://doi.org/10.1007/s10439-023-03304-z]
- A. Hu, L. Gao, and D. Zhu, "Applications of generative models in art and music: A new age of creativity", Proceedings of the International Conference on Computational Creativity, Jönköping, Sweden, pp. 128-137, Jun. 2024.
-
Y. Ko and Y. Kim, "Performance improvement of speech emotion recognition model using generative adversarial networks", Journal of the Korea Institute of Information Technology, Vol. 17, No. 11, pp. 77-85, Nov. 2019.
[https://doi.org/10.14801/jkiit.2019.17.11.77]

2019년 3월 : 한국성서대학교 컴퓨터소프트웨어학과(공학사)
관심분야 : 인공지능, 딥러닝, 컴퓨터비전, 이미지 처리, 의료 인공지능

2019년 3월 : 한국성서대학교 컴퓨터소프트웨어학과(공학사)
관심분야 : 인공지능, 딥러닝, 컴퓨터비전, 이미지 처리

2014년 2월 : 한국성서대학교 컴퓨터소프트웨어학과(공학사)
2023년 2월 : 이화여자대학교 컴퓨터공학(공학박사)
2023년 3월 ~ 현재 : 한국성서대학교 컴퓨터공학과 조교수
관심분야 : 블록체인, 머신러닝, 딥러닝, 네트워크 보안